Revisión de logs críticos para analizar incidentes de seguridad
Aunque esta lista de control de logs puede utilizarse para la revisión rutinaria de logs, este proceso crítico de revisión de logs es una metodología de análisis de respuesta a incidentes de seguridad basada en el trabajo de los investigadores en seguridad informática Dr. Anton Chuvakin y Lenny Zeltser.
La ventaja de utilizar ServicePilot basado en y aplicando esta metodología de seguridad operativa es que estas tareas pueden ser realizadas y automatizadas en un solo software. De este modo, estos análisis automáticos pueden insertarse fácilmente en los procesos de control de rutina para aprovechar la automatización de la revisión de logs y ser más proactivos en la respuesta a los incidentes de seguridad.
Enfoque metodológico general para el análisis de logs críticos
Aquí están los 8 pasos recomendados por estos investigadores así como 2 opcionales que podríamos añadir:
-
Identificar las fuentes de los logs y las herramientas que se utilizarán durante el análisis
-
"Copie" los logs en un solo lugar para examinarlos
-
Minimizar el "ruido" eliminando las entradas repetitivas y rutinarias del diario después de confirmar que son benignas
-
Determinar si se puede confiar en la fecha y hora de los logs; teniendo en cuenta las diferencias horarias
-
Monitorear cambios recientes, fallas, errores, cambios de estado, eventos de acceso y administración y otros eventos ambientales inusuales
-
Retroceder en el tiempo de ahora en adelante para reconstruir las acciones después y antes del incidente
-
Relacionar las actividades entre los diferentes periódicos para obtener una visión global y operativa
-
Desarrolle teorías sobre lo que pasó; explore los periódicos para confirmarlas o refutarlas
-
Automatizar el análisis a gran escala y de forma recurrente
-
Confirmar o negar el impacto en la producción de TI y en el rendimiento del negocio
Análisis automatizado de registros y seguridad con ServicePilot
Identificar las fuentes de log y las herramientas que se utilizarán durante el análisis
Gran parte de la información operativa y de seguridad de una organización puede derivarse de los archivos de log generados por los servidores, equipos y aplicaciones de la empresa.
Fuentes potenciales de logs de seguridad:
- Logs del sistema operativo del servidor y de la estación de trabajo (Syslog, Windows Events, Sysmon Sysinternals...)
- Logs de aplicación (servidor web, base de datos...)
- Logs de herramientas de seguridad (Firewall, AV, IDS, IPS...)
- Logs de proxy y de aplicaciones
- Otras fuentes no registradas de eventos de seguridad (datos de rendimiento, métricas de NetFlow, resultados de script, resultados de comprobación de archivos YARA, etc.).
ServicePilot no sólo recopila registros y eventos (Syslogs, Traps, registros del W3C,...) sino que también ofrece varias interfaces para acelerar el procesamiento y análisis de los registros: cuadros de mando, informes en PDF, alarmas, integraciones de mapas, interfaces personalizables, registradores de eventos en tiempo real e históricos, etc.
Cada nueva fuente o despliegue de colectores, como la recepción de Syslogs o Windows Events de nuevos equipos, se integra automáticamente en los cuadros de mando estándar específicos de cada tecnología. Los filtros, el calendario y la creación de tableros con widgets personalizados facilitan la segmentación de lo que se busca e identifican rápidamente las anomalías en la masa de enlaces que conforman el perímetro de seguridad informática de una empresa.
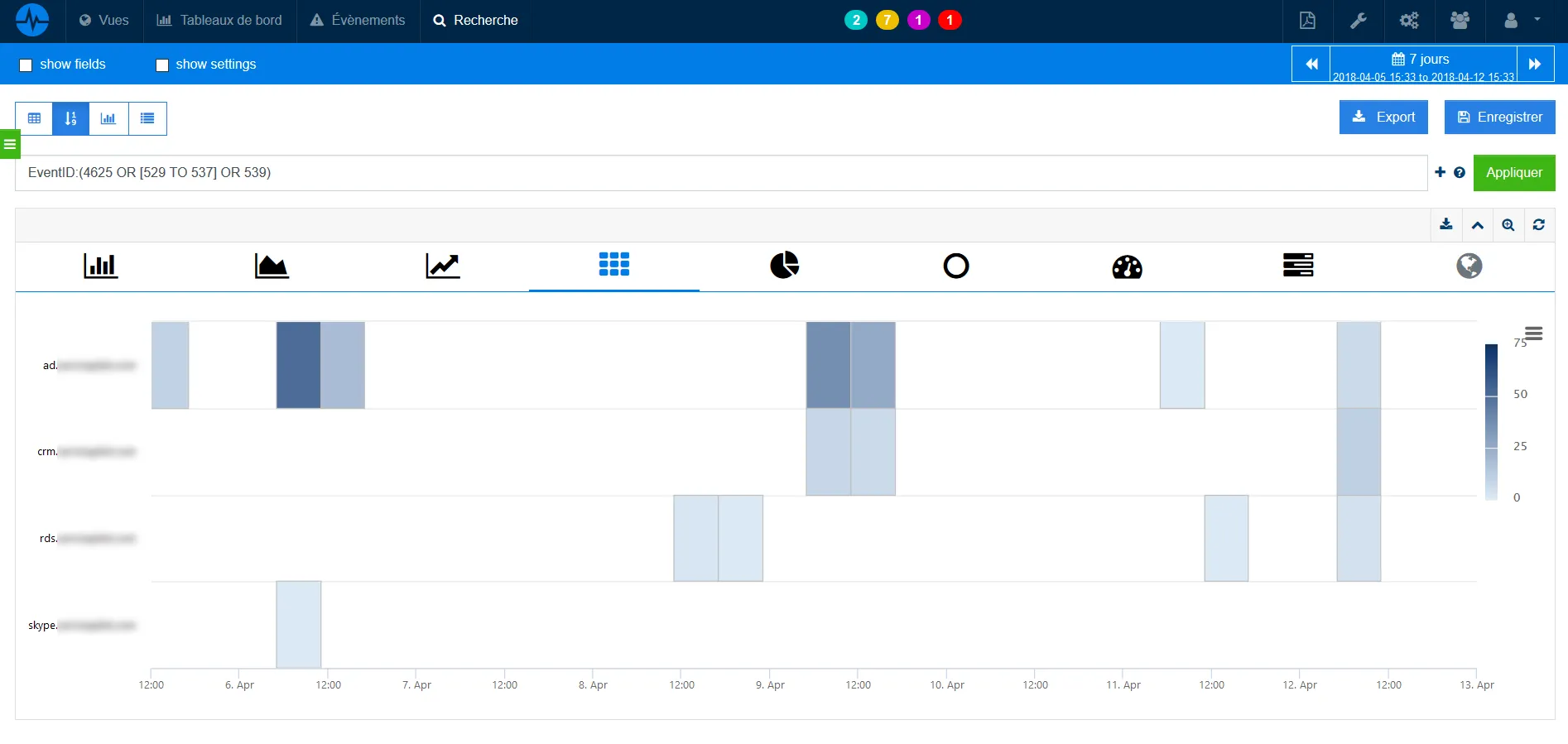
La siguiente captura de pantalla muestra un tablero estándar para el análisis de Eventos de Windows con un top n por servidor, lo que permite investigar un Evento de Windows en particular.

2. Copiar los logs a una sola ubicación para su revisión
Localice sus fuentes de datos y configure ServicePilot a través de YAML o de la interfaz web para enviar/recibir logs y fuentes de eventos de seguridad para gestionar los logs de forma unificada. Es impensable hacer malabares a nivel local en varias máquinas o en entornos complejos y distribuidos para entender lo que está sucediendo.
Aquí están las ubicaciones típicas de los logs:
- Sistema operativo Linux y aplicaciones centrales: /var/log
- Sistema operativo Windows y aplicaciones centrales: logs de eventos de Windows (seguridad, sistema, aplicación, directorio Sysmon, directorio específico, IIS...)
- Dispositivos de red: generalmente grabados a través de Syslog; algunos utilizan ubicaciones y formatos propietarios.
- logs especiales, útiles y patentados; ServicePilot utiliza un análisis natural de algunos campos para logs sin formato; es posible crear paquetes o análisis personalizados para comprender mejor estos mensajes.

Para simplificar el análisis y la correlación posterior, un buen método es crear una view (un tipo de contenedor o caja que contenga elementos dispares y/o homogéneos que desee analizar) del tipo "Analyse-CVE-abc" o "SecurityRoutine-xyz".
En caso de que estas fuentes ya estén recogidas en ServicePilot, podemos simplemente crear un acceso directo a esta fuente o Búsqueda de objetos (búsqueda automatizada en logs que pueden realizar muchas operaciones como recuento, suma, etc.) para evitar problemas de duplicación.
3. Minimizar el "ruido" eliminando las entradas benignas del log
Es esencial ser capaz de minimizar el "ruido" eliminando las entradas repetitivas y rutinarias del diario después de confirmar que son benignas.
A través de filtros y consultas simples, podemos filtrar y reducir la cantidad de eventos para minimizar gradualmente el "ruido" y los eventos menores que interrumpen el análisis. Se pueden utilizar casillas de verificación o filtros de consulta simples para reducir la cantidad de reproducción (especialmente para eventos de Windows...).
Varios pasos y técnicas permiten encontrar la aguja en el paquete de logs, para comprender fácilmente las dependencias y los impactos del incidente, ya sea desde el aprovisionamiento, a través de análisis desde los cuadros de mando, a través de las bandejas de eventos o a través de consultas de aprendizaje automático en el motor de búsqueda de grandes datos ServicePilot (Ejemplo: Aprendizaje automático para el análisis de términos significativos y anamolias en logs y eventos).

Registrar la reducción de ruido con un filtro de petición](/images/blog/blog10_img6.webp "Registrar la reducción de ruido con un filtro de petición")
4. Determinar si se puede confiar en la fecha y hora de los periódicos.
ServicePilot se lo pone fácil y gestiona los sellos de tiempo y la gestión de zonas horarias mediante la indexación de todos los datos en formato UTC y la visualización de la zona horaria correcta en función de la configuración de usuario del navegador web ServicePilot. No hay dolor de cabeza, está hecho para ti!
5. Una vigilancia de los cambios y acontecimientos inusuales en el medio ambiente
Los cambios recientes, fallas, errores, cambios de estado, eventos de acceso y administración y otros eventos ambientales inusuales deben ser monitoreados.
- Qué buscar en Linux
En Linux, puede buscar muchas palabras clave interesantes entre los syslogs para detectarlas automáticamente:
- Conexiones de usuarios con éxito
- Fallos en el inicio de sesión del usuario
- Desconexiones de usuarios
- Modificación o eliminación de cuentas de usuario
- Sudo Acciones o fallos en el servicio
Las consultas prefabricadas que contienen este tipo de búsqueda están disponibles como estándar, y permiten no sólo hacer tops simples, sino también ver el mismo top con un algoritmo de aprendizaje de máquina para analizar términos significativos para las anamolias de superficie (Top con rastrillado de proporciones).
- Qué buscar en Windows
En Windows, los identificadores de eventos son los principales mecanismos para la skimming rápida de eventos. La mayoría de los eventos que se muestran a continuación se encuentran en el log de seguridad; muchos de ellos sólo están registrados en el controlador de dominio, y otros deben activarse porque no están registrados de forma predeterminada. Sin embargo, es fácil hacer las tapas:
- Los eventos de conexión y desconexión del usuario (Inicio de sesión correcto; inicio de sesión fallido; cierre de sesión, etc.),
- Cambios en la cuenta de usuario,
- Cambios de contraseña,
- Servicios iniciados o interrumpidos, etc.
La siguiente captura de pantalla muestra el seguimiento de las conexiones fallidas en varios hosts de Windows a lo largo del tiempo.

ServicePilot también es compatible con el análisis de los logs de Sysmon Sysinternals de Windows, lo que le permite registrar eventos de Windows detallados sobre creaciones de procesos, conexiones de red, eventos de log, creaciones de archivos y mucho más.
- Qué buscar en los dispositivos de red
En los dispositivos de red, es necesario examinar las actividades entrantes y salientes. Los siguientes ejemplos muestran extractos de los logs de Cisco ASA (%ASA); otros dispositivos tienen características similares.
- Tráfico autorizado en el cortafuegos buscando los mensajes: "Construido... conexión", "lista de acceso... permitido".
- Tráfico bloqueado en el firewall buscando mensajes: "access-list .... denied", "deny inbound", "Deny .... by".
- bytes transferidos (¿ficheros grandes?) buscando mensajes: "Teardown TCP connection .... duration... bytes..."
- Uso de ancho de banda y protocolos mediante la búsqueda de mensajes: "Limite ... excedido", "Uso de la CPU", "Utilización de la CPU".
- Actividad de ataque detectada al buscar mensajes: "attack from" (ataque desde)
- Cambiar la cuenta de usuario buscando mensajes: "user added", "user deleted", "User priv level changed".
- Acceso de administrador mediante búsqueda de mensajes: "AAA user...", "User.... locked out", "login failed".
El siguiente ejemplo nos muestra un seguimiento de las autenticaciones exitosas frente a las fallidas de una VPN Cisco de trabajadores remotos.

- Qué buscar en los servidores web
En los servidores web, es necesario prestar atención a muchos parámetros e indicadores para poder localizar fácilmente entre miles o millones de peticiones:
- Intentos excesivos de acceder a archivos inexistentes
- Intentos de acceso al código (SQL, HTML) visto como parte de la URL
- Intentos de acceso a extensiones que no ha implementado
- Mensajes de servicio web detenidos / iniciados / fallidos
- Acceso a páginas "arriesgadas" que aceptan entradas de usuarios
- logs de todos los servidores en el grupo de balanceo de carga
- Códigos de error 200 en archivos que no son suyos
- Fallos en la autenticación de usuarios
- Códigos HTTP 4xx y 5xx......

El poder del piloto de servicio para el análisis
El objetivo es utilizar las consultas preintegradas incluidas en ServicePilot, personalizarlas según nuestro entorno, generar automáticamente informes PDF o cuadros de mando detallados para un análisis en profundidad y una correlación.
Por ejemplo, podríamos crear varios informes genéricos para cada tipo de fuente de datos y un nivel general muy alto para una revisión rápida, así como varios cuadros de mando para un acceso rápido a un análisis detallado.
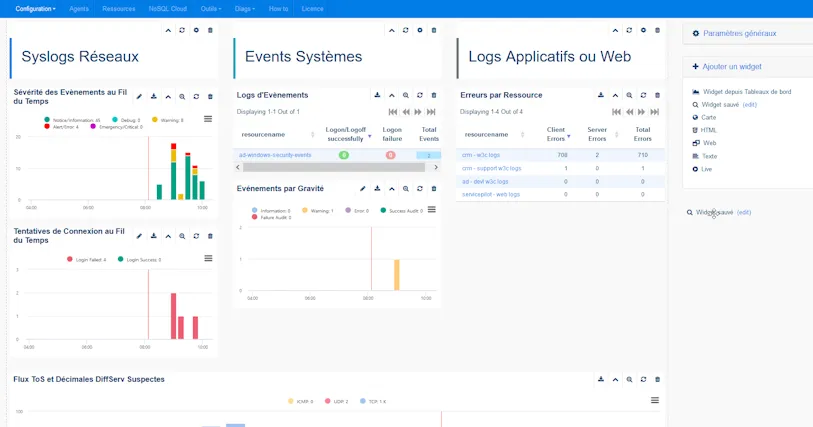
Construir un panel de control global personalizado que monitoree tres fuentes diferentes (por ejemplo, syslogs, Windows Events y alertas de Suricata en formato Syslog) y convertirlo en mi página de inicio es relativamente sencillo con las funciones de arrastrar y soltar de la interfaz web. La construcción de un informe se basa en los mismos principios y comparte tus widgets y gráficos guardados.
Edición de un panel de supervisión de log personalizado
Después de haber centralizado mis fuentes y logs en una vista "SecurityRoutine01", sólo tengo que aplicar la vista de filtro: "SecurityRoutine01" para filtrar cualquier solicitud / panel de control o informar a las fuentes necesarias.
Al haber creado widgets personalizados con los recursos que quiero, no necesito filtrar eventos en un host, una vista, una aplicación o un recurso. También puedo crear nuevas consultas para extender mi análisis al nivel de aplicación (SharePoint, Exchange...) y middleware monitorizando eventos clave de seguridad en Microsoft SQL Server, por ejemplo:
- Cambio de autoridad de administrador
- Cambios en la autorización
- Función de los miembros
- Cambio de la configuración de seguridad
- Fallo de conexión
- Exportación de datos por usuarios privilegiados
El uso de la arquitectura ServicePilot y las funciones nativas de Machine Learning también mejoran el análisis o la reducción del ruido de supervisión. ServicePilot tiene consultas prefabricadas para ir más rápido y obtener y buscar lo que se necesita en cada tecnología para hacer, por ejemplo, análisis de términos significativos y anamolias en logs y eventos.
Análisis de términos y anamolias significativas en logs y eventos](/images/features/17-machine-learning-significative-termesses-analysis.webp "análisis de términos y anamolias significativas en logs y eventos")
6. Retroceder en el tiempo de ahora en adelante para reconstruir las acciones después y antes del incidente.
Después de guardar todas las consultas en el paso anterior para la exportación automática a cuadros de mando e informes, podemos utilizar el calendario en los cuadros de mando o generar informes en PDF para el período de tiempo seleccionado.

7. Correlacionar las actividades entre los diferentes periódicos para obtener una visión global y operativa.
En el menú de creación de dashboards, podemos dividir fácilmente un dashboard en 3 partes, cada una de las cuales representa un tipo de log, una métrica de rendimiento, una vista general de la actividad, una solicitud de seguridad, etc., de acuerdo con sus necesidades.
La función de calendario en la vista del tablero de instrumentos y la orientación gráfica cruzada del ratón facilita la captura de la imagen completa y la correlación de eventos entre las fuentes de log de TI y el "ruido" para centrarse en el análisis de impacto y en las fuentes heterogéneas de correlación de logs o métricas.
Esto se puede hacer mediante cuadros de mando, consultas a través del motor de búsqueda o informes en PDF.
8. Desarrollar teorías sobre lo que sucedió; explorar los periódicos para confirmarlas o refutarlas.
Para desarrollar teorías sobre lo que sucedió una vez que los logs, eventos y fuentes han sido confirmados y seleccionados para el análisis post-legal, podemos construir un modelo de informe en blanco para describir la teoría. Este modelo puede construirse a partir de modelos conocidos de informes de descanso de incidentes de SANS o de informes de incidentes de Pentest. Esto permite unificar y estandarizar el proceso de análisis de incidentes de seguridad. Incluso podemos intentar crear documentación de incidentes de seguridad, simplificar la construcción de la solicitud y enriquecer mis informes semanales automatizados con una nueva revisión automática de inteligencia de seguridad.

9. Automatizar el análisis a gran escala y de forma recurrente
Una vez cerrado el incidente de seguridad, podemos automatizar el análisis de este incidente con una consulta e incluirlo en un informe semanal en PDF (por ejemplo, todos los lunes a las 8 de la mañana se envía a los equipos un Chequeo Semanal de Seguridad en PDF). Esta tarea puede automatizarse fácilmente para las comprobaciones rutinarias con informes programados en PDF que contienen el resultado de la lista anterior de posibles consultas para detectar actividad anormal en toda la pila de TI.

10. Confirmar o negar el impacto en el rendimiento operativo de TI, el enfoque de SecOps para la producción
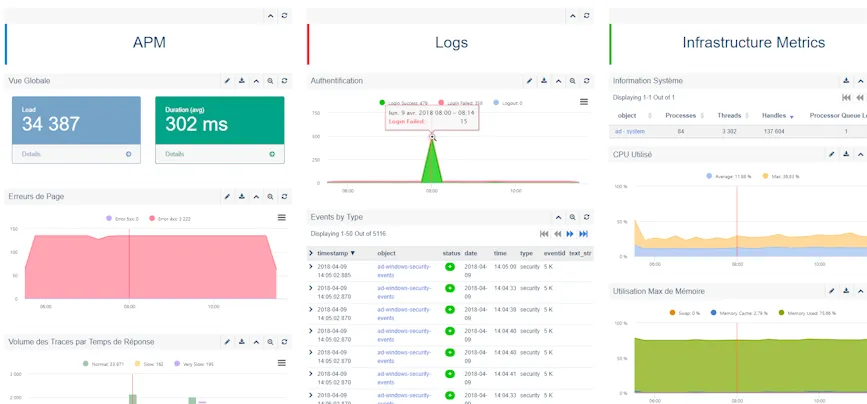
También es útil analizar los impactos de los incidentes de seguridad en el rendimiento operativo de TI durante el periodo del incidente, lo que puede lograrse fácilmente con cuadros de mando y calendarios dedicados. Esto facilita la respuesta a preguntas como: ¿Cuál fue el impacto del evento de seguridad de abc en el tiempo de respuesta de mi aplicación? La siguiente captura de pantalla muestra una visión de DevSecOps para monitorear una aplicación en producción.
Tablero de pila completa de una aplicación APM, seguridad, infraestructura

{kind=link}
{kind=link}