Gestion des problèmes et Root Cause Analysis
Qu'est ce que la fatigue d'alerte ?
La fatigue d'alerte est le phénomène par lequel un volume excessif d’alertes (souvent des faux positifs ou de faible priorité) désensibilise les équipes de supervision entraînant des alertes ignorées, des réponses retardées ou des incidents manqués. Cela survient quand les opérateurs deviennent surchargés par des notifications répétées et peu pertinentes émises par des outils de supervision ou de sécurité. Le résultat est une baisse de vigilance et une augmentation du risque d’erreur humaine.
Comment cela se produit ?
- Trop d’alertes simultanées ou fréquentes
- Faux positifs et alertes de faible priorité non filtrées
- Manque de priorisation et d’escalade claire dans les procédures opérationnelles
Ces facteurs conduisent à la désensibilisation et à des réponses lentes aux alertes réellement critiques. Les conséquences concrètes pour les organisations sont :
- Alertes critiques manquées et délais de résolution accrus
- Découragement et démoralisation des équipes de supervision
- Risque opérationnel et sécurité augmenté
Réduire le MTTR et la fatigue d'alerte dans les SI
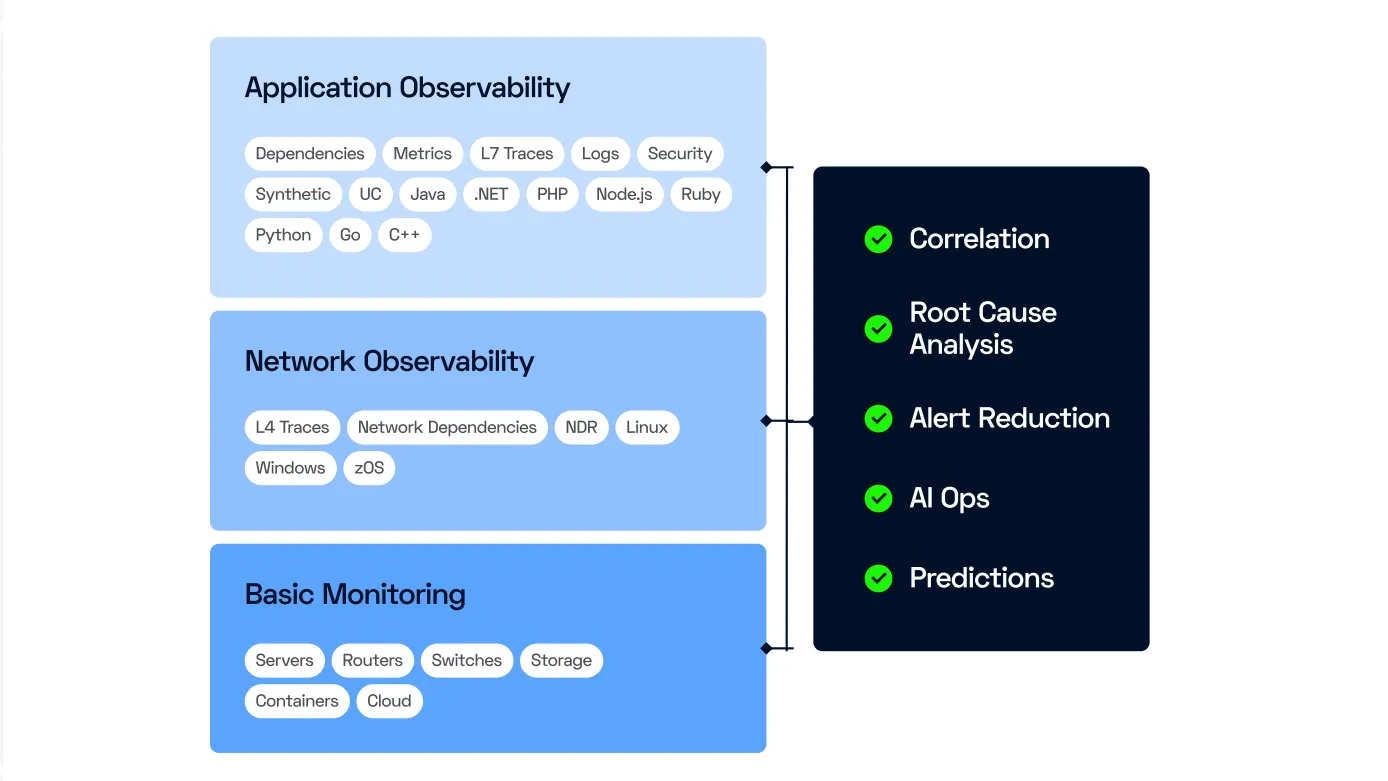
Dans les environnements modernes avec des applications basées sur des architectures type microservices et des infrastructures distribuées hybrides ou hébergées dans le cloud, la gestion efficace des problèmes et l'analyse des causes profondes (RCA) sont cruciales.
Ces architectures complexes nécessitent une surveillance approfondie pour identifier rapidement les incidents et leurs causes sous-jacentes. Cela permet d'éviter les incidents en cascade, de minimiser les temps d'arrêt et d'assurer une performance optimale.
C'est pourquoi ServicePilot v12 introduit un nouveau concept de "Problèmes" qui améliore la gestion des incidents et l'analyse des causes profondes. Cette fonctionnalité permet de corréler intelligemment les alarmes et d'identifier les causes racines avec plus de précision.
Concepts fondamentaux : incident, anomalie, problème, cause profonde
Un incident apparent (ex: un service lent) peut être la conséquence d’un problème plus profond (infra, dépendance, base de données, erreur applicative...). Sans corrélation intelligente, on risque une avalanche d’alertes redondantes (“alert fatigue”), avec une augmentation du bruit qui est en réalité préjudiciable. L’idée est de regrouper ce qui appartient au même “problème”.
Incident / Alerte : tout comportement observable disposant de seuils (lenteur, erreur, saturation, crash, etc.). Lorsqu'un incident significatif est identifié, il est signalé avec un statut critique ou indisponible dans ServicePilot. Un statut critique indique une dégradation significative des performances, tandis qu'un statut indisponible indique une panne.
Anomalie : une anomalie dans les alertes de supervision est un événement ou un comportement qui s’écarte du fonctionnement ou comportement normal attendu d’un système.
Problème : entité logique qui regroupe plusieurs incidents anormaux partageant une même cause racine pour regrouper les symptômes et éviter les doublons d'alertes.
Root Cause Analysis (RCA) : processus visant à identifier la cause sous-jacente à partir des événements et du contexte, pas seulement les symptômes visibles lors d'un incident.
Principes de l’analyse automatique & corrélation
Données utilisées pour grouper et dédupliquer les alertes
Les algorithmes avancés de ServicePilot utilisent des données multiples (métriques, traces, flux, événements) à tous les niveaux (infrastructures, services, applications). La topologie de l’environnement est au cœur de la corrélation pour analyser correctement les dépendances entre services, processus, hôtes, conteneurs, etc.
Afin d'éviter les alertes redondantes et simplifier la gestion des incidents, plusieurs critères de groupage et déduplication sont utilisés :
- Dépendances L4 : les dépendances au niveau 4 (couche transport) sont prises en compte pour regrouper les incidents liés à des connexions réseau spécifiques
- Dépendances L7 : les dépendances au niveau 7 (couche application) permettent de regrouper les incidents basés sur les protocoles applicatifs et les services web
- Même Host : les incidents affectant le même hôte sont regroupés pour une gestion centralisée
- Même LAN : les incidents se produisant dans le même réseau local (LAN) sont également regroupés pour une analyse plus efficace
Corrélation contexte, temporelle et algorithmie
L’analyse ne se limite pas à un simple déclenchement en même temps (timestamp). Elle combine le contexte (dépendances, topologie, appels, transactions) ainsi que les données historiques pour éviter des faux positifs ou conclusions erronées.
Par exemple, si un service A ralentit, puis un service B en aval ralentit, le moteur doit déterminer si c’est la cause ou un autre problème (pas juste “B est lent car A l’était”).
L’approche s’appuie sur ce qu’on appelle “fault tree analysis” : à partir des dépendances connues, l’IA remonte l’arbre de causalité pour identifier la source racine probable.
Le résultat : un “problème” unique regroupant tous les événements liés à la même cause, avec une entité racine identifiée — évite les doublons / alertes multiples pour une même cause.
Cycle de vie d’un “Problème” — de la détection à la résolution
La durée de vie d'un problème dans ServicePilot est gérée de manière dynamique pour assurer une réponse rapide et efficace :
-
La détection d’un premier événement anormal provoque la création d’un “problème”. Un problème est créé automatiquement si une anomalie persiste pendant au moins 3 minutes. Cela permet de s'assurer que les alertes ne sont pas déclenchées par des fluctuations temporaires.
-
Période d’analyse & corrélation : le moteur de ServicePilot recueille les événements associés, élargit le contexte (topologie, dépendances, traces) et trouve la cause racine.
-
Mise à jour du “problem feed” en temps réel : les nouveaux événements liés sont agrégés au même problème s'ils ont la même cause. L'ajout dynamique permet d'ajouter par la suite des événements liés pour fournir une vue complète et contextuelle de l'incident pendant une période de 90 minutes maximum après la création du problème.
-
La clôture automatique du problème survient quand toutes les entités affectées reviennent à la normale avec une possibilité de réouverture automatique si les symptômes réapparaissent dans un délai de 30 minutes (reopening window).
Valeur ajoutée pour les équipes DevOps / SRE / IT
En utilisant les nouvelles alertes sur des problèmes, les bénéfices pour les équipes de supervision sont nombreux :
- Meilleure priorisation & triage : en combinant impact + root cause + contexte, les équipes peuvent décider ce qu’il faut traiter en priorité
- Moins de “bruit” d’alertes : en regroupant plusieurs événements dans un seul problème, on évite la surcharge d’alertes redondantes pour une même cause
- Analyse approfondie (infrastructures, applications, base de données, dépendances) : possibilité d’identifier des causes profondes complexes (par exemple mémoire, Garbage Collector, requêtes base de données, conteneurs, infra, etc.)
- Réduction du MTTR (Mean Time To Repair) : l’automatisation et la corrélation réduisent le temps passé à diagnostiquer
La nouvelle fonctionnalité ServicePilot v12 transforme des flux d’alertes bruyants en problèmes actionnables, identifie des causes racines avec précision et oriente les équipes vers les actions à plus fort impact — un levier concret pour fiabiliser les systèmes distribués et accélérer la résolution des incidents.
