Diagrama de flujo automático: 5 funciones clave para su supervisión
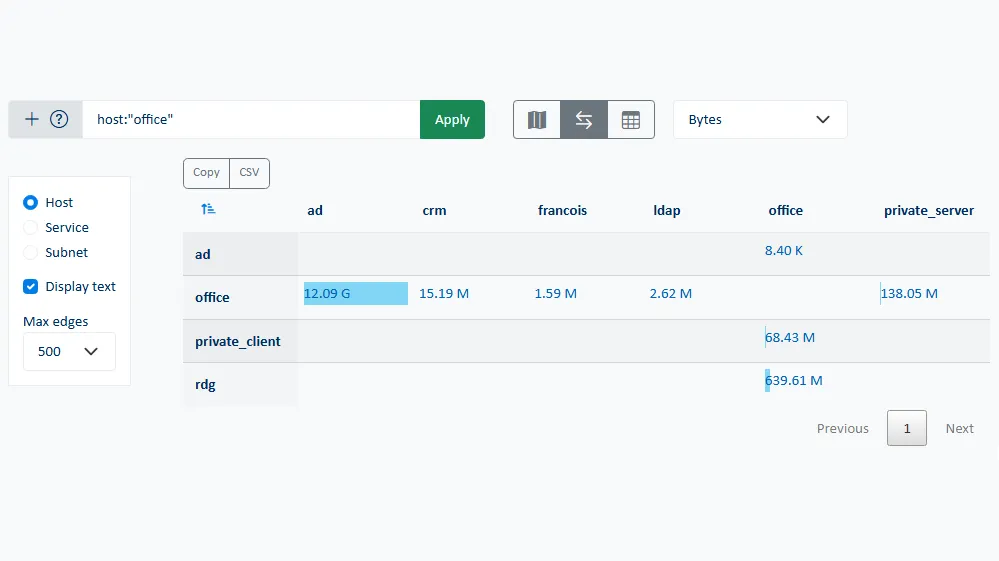
Observabilidad: Comprensión del diagrama de flujo de red
Un diagrama de flujos es una representación visual y estructurada del conjunto de comunicaciones entre servidores, aplicaciones, servicios y procesos. Permite visualizar, de un solo vistazo, quién se comunica con quién, en qué puertos, a través de qué protocolos y con qué intensidad. Las tablas y los mapas dinámicos se convierten en una herramienta fundamental para comprender las dependencias de las aplicaciones, identificar las rutas críticas y analizar el comportamiento real de los sistemas en producción.
Los casos de uso son numerosos :
- En la segmentación de redes, el diagrama de flujos permite validar las reglas de filtrado, detectar comunicaciones inesperadas y preparar proyectos Zero Trust.
- En materia de seguridad, pone de relieve los flujos anormales, las comunicaciones laterales sospechosas o los comportamientos desviados.
- Para los equipos de aplicaciones, revela las dependencias reales entre microservicios, bases de datos y componentes de terceros.
- Por último, durante la resolución de problemas, acelera la identificación del origen de una ralentización o un fallo, mostrando inmediatamente dónde se bloquea o se degrada un flujo.
Las matrices de flujo tradicionales, que suelen basarse en exportaciones NetFlow, sFlow o sondas de red, presentan importantes limitaciones. Dependen de la visibilidad que ofrece la infraestructura, no siempre capturan las comunicaciones internas de los servidores y carecen de contexto aplicativo. En entornos virtualizados, contenedorizados o multicloud, estos enfoques tienen dificultades para seguir la realidad de los intercambios, ya que un mismo flujo puede atravesar varias capas lógicas antes de ser visible.
Por eso, un diagrama de flujo construida directamente a partir de los servidores y los procesos ofrece una precisión mucho mayor. Al observar el tráfico en el origen (a nivel del kernel, del proceso y de la aplicación), permite relacionar cada comunicación con su origen real, identificar el servicio implicado y comprender la finalidad del flujo. Este enfoque elimina las zonas oscuras, garantiza una visibilidad completa incluso en arquitecturas complejas y proporciona una base fiable para la supervisión, la seguridad y la optimización del rendimiento.
La tecnología NetTrace de ServicePilot se basa precisamente en este enfoque: observar el tráfico directamente a nivel del servidor y del proceso para producir un diagrama de flujos completa, contextualizada y inmediatamente explotable. Esta visibilidad detallada permite comprender las dependencias reales, identificar anomalías y obtener una supervisión verdaderamente unificada.
5 funciones clave para el análisis del tráfico y el diagrama de flujo
Aquí hay cinco características esenciales que toda solución de observabilidad debería ofrecer para proporcionar una visión fiable, detallada y procesable del tráfico de sus sistemas.
1. Recopilación de tráfico multiplataforma e independiente de la red
Una solución de observabilidad verdaderamente operativa debe recopilar el tráfico directamente en las interfaces del sistema, sin depender de equipos intermedios. NetTrace permite este enfoque al integrarse de forma nativa en Windows y Linux, ya sea en servidores bare-metal, máquinas virtuales, infraestructuras hipervisadas, contenedores u orquestadores como Kubernetes.
Esta recopilación local ofrece varias ventajas técnicas. En primer lugar, captura la totalidad de los flujos de redes, incluidos aquellos que nunca salen del nodo, como las comunicaciones entre procesos encapsuladas o los flujos internos de un clúster. También elimina la pérdida de información relacionada con los proxys de red, los overlays, los túneles SD-WAN o los mecanismos NAT que dificultan la interpretación de los flujos desde el exterior. Por último, garantiza que el análisis siga siendo coherente incluso cuando la red está segmentada, cifrada, enrutada dinámicamente o admite mecanismos de equilibrio avanzados.
Esta independencia de la infraestructura de red es una condición esencial para obtener una visión fiable en entornos modernos, incluso en las arquitecturas más segmentadas o distribuidas.
En resumen: una recopilación unificada, fácil de implementar y inmediatamente explotable.
2. Diagrama de flujo automático para una supervisión unificada
Recopilar datos es una cosa, pero hacerlos legibles, accesibles y explotables es otra muy distinta.
Las infraestructuras modernas se caracterizan por una heterogeneidad cada vez mayor: multiplicidad de servidores, diversidad de zonas de red, hibridación entre la nube y las instalaciones locales, mecanismos de resiliencia distribuida. En este contexto, disponer de una visión centralizada del tráfico se vuelve indispensable para correlacionar los comportamientos entre varios perímetros.
NetTrace consolida en tiempo real la información recopilada en todos los servidores y la muestra a través de una interfaz unificada. Esta vista agregada permite observar la actividad global de la red, pero también navegar con fluidez desde el nivel macro (topología funcional, flujos dominantes, volúmenes) hasta el nivel micro (proceso individual, socket específico, consulta de un servicio). Las visualizaciones dinámicas permiten seguir las variaciones de carga en tiempo real, identificar los servidores más solicitados o seguir la evolución de un flujo concreto a lo largo de su vida útil.
Esta centralización de la supervisión simplifica considerablemente la resolución de problemas, ya que permite visualizar las dependencias entre servicios sin tener que mantener manualmente matrices de flujos o mapas estáticos. Permite asociar una degradación observada en una aplicación a un fenómeno de red concreto, identificar picos de rechazos o retransmisiones TCP, así como detectar un aumento de la latencia relacionado con un cambio de comportamiento de un servicio externo.
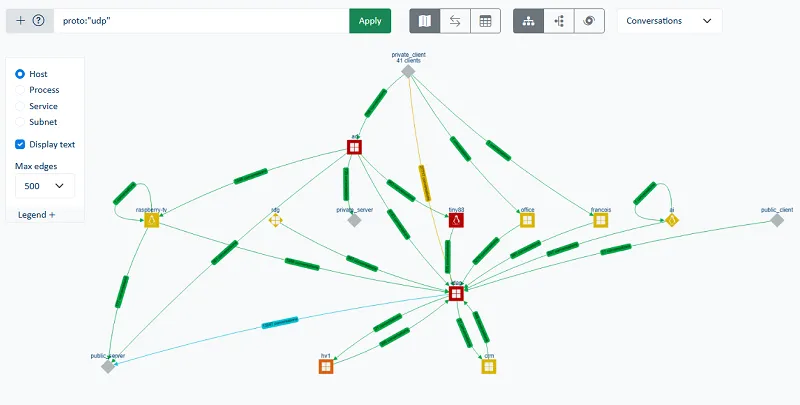
Esta centralización simplifica considerablemente la resolución de problemas, ya que permite visualizar las dependencias entre servicios sin tener que mantener manualmente matrices de flujo o mapas estáticos. Permite asociar el deterioro observado en una aplicación a un fenómeno de red concreto, identificar picos de rechazos o retransmisiones TCP, así como detectar un aumento de la latencia relacionado con un cambio en el comportamiento de un servicio externo.
De este modo, los equipos de TI pueden identificar en cuestión de segundos:
- Los servidores más solicitados
- Los flujos entrantes y salientes dominantes
- Las dependencias entre aplicaciones
- Ls interacciones entre recursos internos y servicios externos
Con una vista consolidada del tráfico, la correlación entre los eventos de red y el comportamiento de las aplicaciones se vuelve sencilla y rápida, lo que supone una gran ventaja para la resolución de problemas y la optimización continua.
3. Análisis granular por servidor, aplicación y proceso
La verdadera dificultad del análisis de red no reside en la recopilación, sino en la interpretación. Un flujo TCP en un puerto determinado no significa nada hasta que se sabe qué proceso lo ha emitido, para qué aplicación sirve, cuándo se ha iniciado y durante cuánto tiempo. Las herramientas de red tradicionales suelen detenerse antes de llegar a este nivel de detalle y dejan que los equipos de sistemas/DevOps se encarguen de establecer correlaciones manuales.
ServicePilot NetTrace adopta un enfoque totalmente diferente. Mediante la observación directa de la pila TCP/IP del sistema, conecta cada socket a su proceso padre, identificando el ejecutable, la ruta del binario, el usuario asociado e incluso la instancia de la aplicación en un entorno multiservicio. Esta capacidad de contextualizar los flujos a nivel de proceso es crucial para distinguir el tráfico empresarial del tráfico del sistema. Permite, por ejemplo, diferenciar el tráfico generado por una base de datos PostgreSQL, por un módulo de supervisión o por un componente de aplicación de terceros que se ejecuta en el mismo servidor.
Esto permite responder a preguntas clave cuando se quiere analizar el comportamiento de un servidor, tales como:
- ¿Qué aplicación consume más ancho de banda?
- ¿Qué procesos generan tráfico inusual o no autorizado?
- ¿Qué puertos se utilizan realmente y por qué aplicaciones?
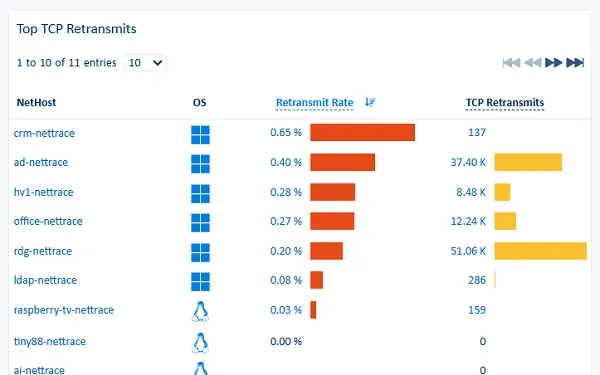
- ¿Cuáles son las tasas de retransmisiones, rechazos y reinicios para tal o cual servicio?
Esta granularidad transforma una visión global («el servidor A ha generado 10 GB de tráfico durante 25 minutos») en información útil («el proceso B del servidor A ha intercambiado 10 GB con la base de datos D del servidor C desde el puerto E durante 25 minutos»).
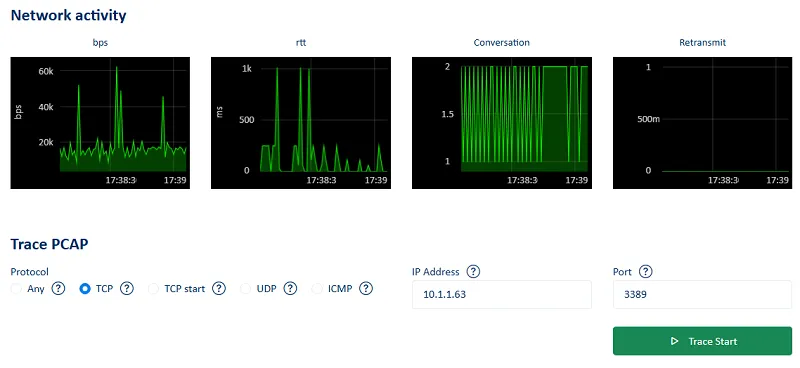
NetTrace le permite capturar datos de paquetes en tiempo real (PCAP) directamente desde el navegador. Con un solo clic, puede iniciar un rastreo en cualquier servidor y descargar los rastros de los paquetes para realizar un análisis detallado.
Llegar a este nivel de detalle cambia radicalmente la comprensión del comportamiento de la red. Se puede observar en tiempo real qué aplicaciones saturan el ancho de banda, qué procesos establecen conexiones inesperadas o qué etapas de las aplicaciones consumen más recursos de red en un flujo de trabajo determinado. En entornos compartidos con instancias o servicios a veces efímeros, esta capacidad aporta una transparencia indispensable para atribuir con precisión el consumo de red a un servicio determinado.
El resultado: un diagnóstico más rápido, una mayor comprensión del negocio y un refuerzo natural de la seguridad.
4. Detección automática de anomalías y comportamientos sospechosos
Uno de los principales retos del análisis del tráfico es la detección de comportamientos anormales, ya se trate de un incidente técnico o de una actividad potencialmente maliciosa. En un servidor de aplicaciones, un aumento repentino del número de conexiones salientes, una transferencia masiva e inusual o una solicitud excesiva de un servicio externo pueden revelar un fallo, una configuración incorrecta o una violación de las políticas de seguridad.
NetTrace integra una lógica de detección basada en la observación de las variaciones del tráfico a lo largo del tiempo, la detección de desviaciones con respecto al comportamiento habitual de un proceso y la identificación de conexiones que se salen de los patrones esperados. Este mecanismo permite señalar rápidamente flujos atípicos, comunicaciones con direcciones con las que nunca se ha contactado anteriormente o volúmenes que superan ampliamente los márgenes normales de funcionamiento.
Esta capacidad es esencial para reforzar la postura de seguridad. Al observar los flujos desde el punto de vista del servidor, NetTrace detecta lo que los equipos de red no siempre ven: procesos legítimos que se comportan de forma anómala, servicios desviados, descargas discretas, transferencias internas inusuales o señales débiles de exfiltración. Este enfoque centrado en el servidor constituye una base sólida para la ciberobservabilidad, indispensable para mantener un alto nivel de control en entornos distribuidos en crecimiento exponencial.
5. Historial de datos, tendencias y previsiones
La supervisión moderna no se limita a reaccionar ante los incidentes, sino que también debe permitir anticiparse. El análisis del tráfico a lo largo del tiempo constituye una rica fuente de datos para estudiar la evolución de las cargas, comprender las variaciones estacionales y prever las necesidades futuras.
NetTrace conserva un historial detallado de los flujos por servidor, aplicación y proceso. Esta información no solo sirve para analizar incidentes pasados, sino que también permite identificar ciclos de tráfico, medir el crecimiento de un servicio o detectar la aparición progresiva de nuevos flujos. La observación de estas tendencias facilita la planificación de la capacidad, especialmente cuando se trata de prever aumentos de carga, redistribuir determinados servicios o evaluar el impacto de una migración o un cambio de configuración.
Esta dimensión analítica transforma el tráfico de red en un verdadero indicador estratégico. En lugar de observar puntualmente una saturación o una variación de la carga, los equipos disponen de una visión continua y contextualizada del comportamiento de la red a lo largo del tiempo. De este modo, pueden tomar decisiones informadas, optimizar los recursos y adaptar la arquitectura antes de que las limitaciones se vuelvan cuellos de botella.
Diagrama de flujos dinámico: un pilar de la observabilidad moderna
El diagrama de flujo y el análisis del tráfico ya no son herramientas reservadas a los expertos en redes. Hoy en día, son elementos fundamentales de cualquier estrategia de observabilidad para combinar rendimiento, seguridad y comprensión de las aplicaciones.
La tecnología NetTrace de ServicePilot proporciona un nivel de precisión y contexto indispensable en los sistemas distribuidos actuales. Al combinar la recopilación multiplataforma, la visualización consolidada, la granularidad de las aplicaciones, la detección de anomalías y el análisis histórico, es un elemento esencial para la supervisión.
Gracias a este enfoque, los equipos de TI disponen por fin de una visión clara de lo que realmente ocurre en los servidores y pueden correlacionar con precisión los fenómenos de red con el comportamiento de las aplicaciones. Esta comprensión detallada es fundamental para reforzar el rendimiento, mejorar la resiliencia y garantizar la seguridad de los sistemas a largo plazo.
La observabilidad del tráfico del sistema se convierte en una herramienta estratégica y sus decisiones ganan en precisión.
