Observabilidad de las aplicaciones
Los pilares de la observabilidad
La observabilidad es esencial para garantizar la fiabilidad, el rendimiento y la resistencia de las aplicaciones y las infraestructuras. Permite a los equipos diagnosticar y resolver problemas de aplicaciones de forma proactiva mediante la recopilación y el análisis de datos procedentes de diversas fuentes, como métricas, trazas y logs.
En el contexto del desarrollo de aplicaciones modernas, la observabilidad se refiere a la recopilación y el análisis de estos datos para proporcionar información detallada sobre el comportamiento de las aplicaciones. Es esencial para las arquitecturas dinámicas actuales y los entornos informáticos multi-Cloud, permitiendo a los equipos de ingeniería de software, TI, DevOps y SRE colaborar para tomar decisiones rápidas basadas en datos telemétricos.
ServicePilot puede basarse en 5 tipos principales de supervisión para ofrecer una observabilidad completa de las aplicaciones:
El tracing distribuido rastrea las transacciones y las llamadas entre microservicios o componentes de una aplicación, midiendo con precisión la latencia y las dependencias. Esto permite identificar cuellos de botella o servicios que fallan.
Observación de flujos de red en servidores o hosts permite conocer el tráfico entre aplicaciones, los volúmenes intercambiados, los tiempos de respuesta de la red, las errores de conectividad y los comportamientos sospechosos.
RUM recoge datos directamente de los navegadores o aplicaciones móviles de usuarios reales. Esto nos permite comprender su experiencia (tiempos de carga, errores JS, lentitud…) en el contexto real de uso.
Este tipo de monitoreo simula las rutas de los usuarios mediante scripts o robots. Permite probar continuamente la disponibilidad, la latencia y el comportamiento funcional de los servicios, independientemente del tráfico real.
El análisis centralizado de los logs (sistema, aplicación, seguridad…) permite diagnosticar incidentes, mejorar las alertas o investigar comportamientos anómalos.
Cada pilar cubre una faceta específica del entorno digital. Al combinarlos, ServicePilot permite:
- La correlación inteligente de datos
- La detección proactiva de anomalías
- RCA (Root Cause Analysis) rápido y pertinente
- Observabilidad orientada a la experiencia de los usuarios
Trazas distribuidas
¿Qué es el tracing de aplicaciones?
En arquitecturas dinámicas basadas en microservicios y componentes distribuidos, comprender la ruta completa de una solicitud de usuario a través de la aplicación puede ser un gran desafío. Los rastros de aplicaciones permiten seguir cada solicitud, desde el frontend hasta el backend, registrando su recorrido a través de todos los servicios, API, bases de datos y Hosts involucrados. Proporcionan un mapa detallado y cronológico de los intercambios entre los componentes.
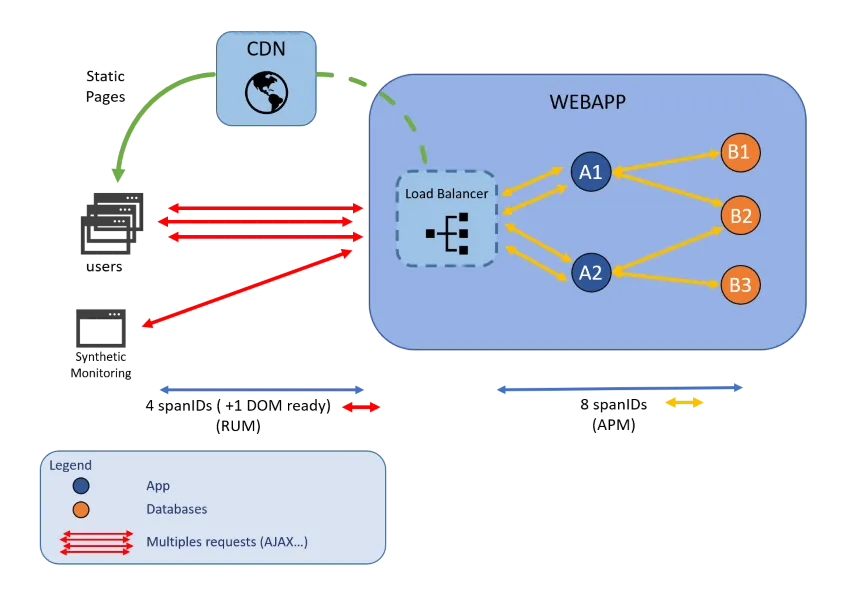
En un entorno compuesto por decenas o incluso cientos de microservicios, cada acción del usuario (como cargar una página o validar un formulario) puede desencadenar llamadas en cascada entre servicios. Las páginas estáticas pueden ser servidas por CDN, las solicitudes pueden depender de sub-solicitudes en bases de datos…
Gracias a las tecnologías AppTrace, se puede supervisar fácilmente:
- Las relaciones cliente/servidor (quién llama a quién)
- Cuánto tiempo lleva cada etapa de una solicitud
- Dónde se producen las ralentizaciones o los errores en el proceso de ejecución
Se puede visualizar la cadena completa de ejecución de una transacción compleja y aislar rápidamente:
- Servicios lentos o sobrecargados
- Dependencias externas defectuosas
- Timeouts o llamadas bloqueadas
Recopilación de trazas y datos de APM
La instrumentación de las aplicaciones es un paso esencial para habilitar el rastreo distribuido (APM) y recopilar trazas precisas de tus aplicaciones. Con ServicePilot, este proceso puede ser rápido, flexible y adaptable, incluso en entornos complejos.
- Configura la aplicación para que envíe trazas, métricas y registros a un Agente ServicePilot mediante OTPL (OpenTelemetry Protocol) sobre http/protobuf, Datadog o las API de Zipkin/HTTP. Consulta a continuación los detalles por lenguaje y marco de trabajo.
- Configura el Agente ServicePilot para que escuche los rastros de la aplicación estableciendo una Regla de provisioning automática en CONFIGURACIÓN > Parámetros > Provisioning-auto. Añade o edita una regla de provisioning automática con el Puerto AppTrace activado y los puertos de escucha correctos especificados.
- Por último, crea una Regla APM desde Parámetros para refinar las definiciones de la aplicación y los detalles de instrumentación.
Si una aplicación ya está instrumentada con un estándar de rastreo de código abierto como OpenTelemetry, Datadog o Zipkin, ServicePilot puede integrarse de forma nativa para recopilar trazas de APM a partir de la instrumentación existente.
Si la aplicación aún no está instrumentada:
- Los administradores pueden instrumentar sus aplicaciones automáticamente mediante una configuración de OpenTelemetry Zero-code o mediante las bibliotecas de instrumentación automática de aplicaciones del SDK de DataDog.
- Los desarrolladores pueden utilizar la API y el SDK de OpenTelemetry para instrumentar sus aplicaciones y enviar métricas, trazas y registros a un Agente ServicePilot. Los datos pueden enviarse directamente a un agente de ServicePilot o agregarse mediante un colector de OpenTelemetry y, a continuación, exportarse a un Agente ServicePilot.
Modos de instrumentación y lenguajes
| Lenguaje | Documentación |
|---|---|
| .NET | Instrumentación zero-code .NET |
| Go | Instrumentación zero-code Go |
| Java | Instrumentación zero-code Java |
| JavaScript | Instrumentación zero-code JavaScript |
| PHP | Instrumentación zero-code PHP |
| Python | Instrumentación zero-code Python |
Entre otros ajustes, se necesitan los siguientes parámetros para la integración con ServicePilot:
OTEL_DOTNET_AUTO_INSTRUMENTATION_ENABLED="true"
OTEL_DOTNET_AUTO_TRACES_INSTRUMENTATION_ENABLED="true"
OTEL_DOTNET_AUTO_METRICS_INSTRUMENTATION_ENABLED="true"
OTEL_DOTNET_AUTO_LOGS_INSTRUMENTATION_ENABLED="false"
OTEL_TRACES_EXPORTER="otlp"
OTEL_METRICS_EXPORTER="otlp"
OTEL_METRIC_EXPORT_INTERVAL="60000"
OTEL_LOGS_EXPORTER="none"
OTEL_EXPORTER_OTLP_ENDPOINT="http://<ServicePilot Agent host IP address>:4318"
OTEL_INSTRUMENTATION_HTTP_SERVER_CAPTURE_REQUEST_HEADERS="Content-Length,Transfer-Encoding,Range,Request-Range,Connection,Host,Accept,x-up-devcap-post-charset,Cache-Control,Referer,X-Filename"
OTEL_EXPORTER_OTLP_PROTOCOL="http/protobuf"
OTEL_EXPORTER_OTLP_TIMEOUT="10000"
| Lenguaje | Documentación |
|---|---|
| Java | Tracing para aplicaciones Java |
| Python | Tracing para aplicaciones Python |
| Ruby | Tracing para aplicaciones Ruby |
| Node.js | Tracing para aplicaciones Node.js |
| .NET Core | Tracing para aplicaciones .NET Core |
| .NET Framework | Tracing para aplicaciones .NET Framework |
| PHP | Tracing para aplicaciones PHP |
Para la integración con ServicePilot se necesitan los siguientes parámetros:
DD_AGENT_HOST="<ServicePilot Agent host IP address>"
DD_TRACE_CLIENT_IP_ENABLED="true"
DD_RUNTIME_METRICS_ENABLED="true"
DD_PROFILING_ENABLED="false"
DD_TRACE_HEADER_TAGS="Content-Length,Transfer-Encoding,Range,Request-Range,Connection,Host,Accept,x-up-devcap-post-charset,Cache-Control,Referer,X-Filename"
Zipkin Tracers and Instrumentation documenta las bibliotecas que permiten la instrumentación del código de las aplicaciones para enviar trazas a un Agente ServicePilot.
| Lenguaje | Documentación |
|---|---|
| C# | Zipkin4net |
| Go | Zipkin Library for Go |
| Java | Brave |
| JavaScript | Zipkin JS |
| Ruby | ZipkinTracer: Zipkin client for Ruby |
| Scala | zipkin-finagle |
Utiliza el protocolo Zipkin/HTTP para exportar datos a un agente de ServicePilot en el puerto TCP 9411
Los desarrolladores pueden utilizar las bibliotecas de instrumentación de OpenTelemetry para integrar trazas, métricas y registros en su aplicación.
| Lenguaje | Documentación |
|---|---|
| C++ | Instrumentación de código C++ |
| C#/.NET | Instrumentación de código .NET |
| Erlang/Elixir | Instrumentación de código Erlang/Elixir |
| Go | Instrumentación de código Go |
| Java | Instrumentación de código Java |
| JavaScript | Instrumentación de código JavaScript |
| PHP | Instrumentación de código PHP |
| Python | Instrumentación de código Python |
| Ruby | Instrumentación de código Ruby |
| Swift | Instrumentación de código Swift |
También hay disponibles integraciones existentes para aplicaciones y marcos de trabajo.
- Bibliotecas de instrumentación alojadas en los archivos de OpenTelemetry.
- OpenTelemetry mantiene una lista de integraciones de instrumentación de OpenTelemetry en su registro.
Visualización de los datos de las trazas APM
Los datos recopilados están disponibles desde varias interfaces de ServicePilot, que ofrecen tanto cuadros de mando globales como interfaces específicas para un diagnóstico contextualizado.
Los cuadros de mando estándar de los logs APM están disponibles con vistas consolidadas o individuales en la sección DASHBOARDS en AppTrace > AppService o AppHost o AppSummary en función de la granularidad de supervisión deseada.
- Los datos recopilados se pueden consultar de forma global seleccionando la categoría deseada.

- Los datos también se pueden consultar para un elemento específico de una categoría.
Más interfaces permiten una exploración granular de las sesiones en la sección DASHBOARDS en AppTrace > Consultas, AppTrace > Aplicaciones, AppTrace > L7 Map o AppTrace > Profiler.
Cuando la columna Traceid contiene un icono de lupa, se puede realizar un drill-down hacia la traza APM para mostrar los detalles de las transacciones de una consulta.
La página AppTrace Consultas ofrece un análisis detallado de las transacciones de las aplicaciones. Los datos presentados ofrecen un análisis preciso del rendimiento y el comportamiento de las aplicaciones, en particular con el número de consultas por minuto por transacción, la satisfacción del usuario y otras métricas de las aplicaciones.
Gracias a la página AppTrace L7 Map, se crea una visualización relacional por sección de sus diferentes sistemas. Es posible identificar los diferentes problemas que podrían encontrar las aplicaciónes supervisadas. A continuación, gracias a la visualización de la arquitectura, puede encontrar rápidamente qué servidor o servicio es el origen del incidente para resolver el problema lo antes posible.
Flujos de red
¿Qué son los flujos de red de los Hosts?
NetTrace es la tecnología de ServicePilot que permite capturar y analizar en profundidad los intercambios de red entrantes y salientes de una máquina (Windows / Linux / IBM z/OS). Al supervisar los flujos de red de varios servidores, se pueden observar los intercambios entre grupos de Hosts y entre los componentes de aplicación de los sistemas.
Gracias a la supervisión de los flujos de red en los servidores y/o contenedores, se puede analizar:
- ¿Quién habla con quién?
- ¿En qué puertos y protocolos?
- ¿Con qué frecuencia?
- ¿Con qué volúmenes de datos?
El Agente ServicePilot captura los flujos IP y genera resúmenes estructurados de las conversaciones de red, además de interfaces detalladas en tiempo real. Las interfaces web proporcionan visualizaciones claras e interactivas de las comunicaciones de red dentro de las infraestructuras.
¿Para qué sirve?
NetTrace es una herramienta de visibilidad de red orientada a las aplicaciones que permite, entre otras cosas:
- Mapear las dependencias entre aplicaciones, servicios, servidores o microservicios.
- Identificar problemas: latencia, saturación, retransmisiones TCP, errores, etc.
- Detectar comportamientos anormales o sospechosos: intercambios inesperados, puertos no estándar, flujos hacia el exterior, etc.
- Validar la conformidad de los flujos de red (en relación con las normas de seguridad, segmentación, cortafuegos o zonas de confianza).
- Unificar la supervisión de los flujos de los sistemas, independientemente de la opción de alojamiento elegida (Nube, Híbrida, On-Premise).
Recopilación de datos de flujos de red
Para recopilar las trazas de red, simplemente instale un Agente ServicePilot en los Hosts que se desean supervisar. Entonces, hay que crear una regla de aprovisionamiento automático marcando la casilla NetTrace desde la interfaz de ServicePilot, debajo la sección CONFIGURACIÓN en Parámetros > Provisioning-auto.
Visualización de los datos de NetTrace
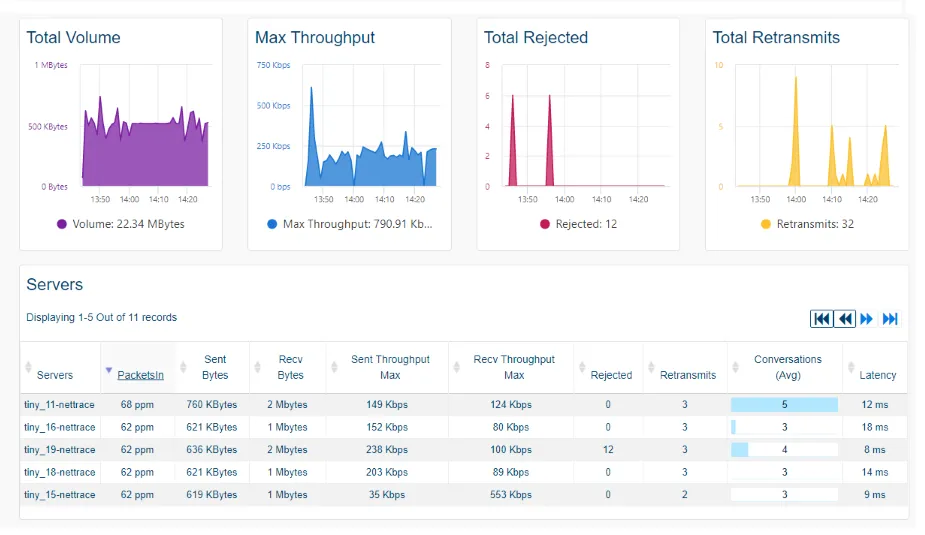
Los datos recopilados están disponibles desde varias interfaces de ServicePilot, que ofrecen tanto cuadros de mando globales como interfaces específicas para un diagnóstico contextualizado.
Los cuadros de mandos estándar de los flujos de servidores/aplicaciones están disponibles con vistas consolidadas o individuales en la sección DASHBOARDS en NetTrace > NetHost o NetProcess en función de la granularidad de supervisión deseada.
Más interfaces permiten una exploración detallada de las conversaciones en la sección DASHBOARDS en NetTrace > Conversaciones, L4 Map, Public o PCAP.
La página Conversaciones de NetTrace permite visualizar las diferentes conexiones establecidas entre los servidores y/o las aplicaciones supervisadas por los Agentes ServicePilot. La columna de filtros permite orientar las búsquedas filtrando por IP, puerto, protocolo, etc. para observar los datos precisos del tráfico de red (conversaciones, conexiones bloqueadas, rechazadas, bytes por segundo, etc.).
Gracias a la página L4 Map, se crea una visualización relacional por sección de sus diferentes sistemas. Es posible identificar los diferentes problemas que podrían encontrar los sistemas supervisados en su red. A continuación, gracias a la visualización de la arquitectura, puede encontrar rápidamente qué servidor o servicio es el origen del incidente para resolver el problema lo antes posible.
La página Público de NetTrace muestra las comunicaciones entrantes/salientes desde/hacia direcciones IP públicas.
La página PCAP de NetTrace ofrece una visualización precisa y rápida de todo el tráfico que transita en directo por una red. Tras seleccionar una red o un Host, es posible visualizar los datos y los diferentes enlaces asociados de varias maneras, en forma de tabla o de gráficos, para obtener una visión general en tiempo real del estado de la red seleccionada. Esta página PCAP también ofrece una función muy interesante que permite capturar el tráfico de red en un equipo en cualquier momento y convertirlo en un rastro PCAP según diversos filtros que se pueden configurar (IP, puertos, protocolo, etc.) y descargar automáticamente desde el navegador.
Real User Monitoring
¿Qué es el Real User Monitoring?
Real User Monitoring (RUM) le permite observar el rendimiento y el comportamiento de los usuarios reales de sus aplicaciones web, directamente desde su navegador. A diferencia de el Synthetic Monitoring, que se basa en pruebas simuladas, RUM mide la experiencia del usuario tal y como es en realidad, teniendo en cuenta las condiciones de la red, el tipo de terminal, la geografía y el entorno del cliente.
Con el RUM, ServicePilot recopila datos valiosos como :
- Tiempos de carga de la página
- Errores de JavaScript encontrados
- El rendimiento de la red y de las aplicaciones
- Geolocalización de los usuarios
- Tipos de navegador, SO y resolución de pantalla
Esto permite comprender, medir y mejorar permanentemente la experiencia real del usuario, tanto desde el punto de vista técnico como ergonómico.
¿Qué es el RUM Session Replay?
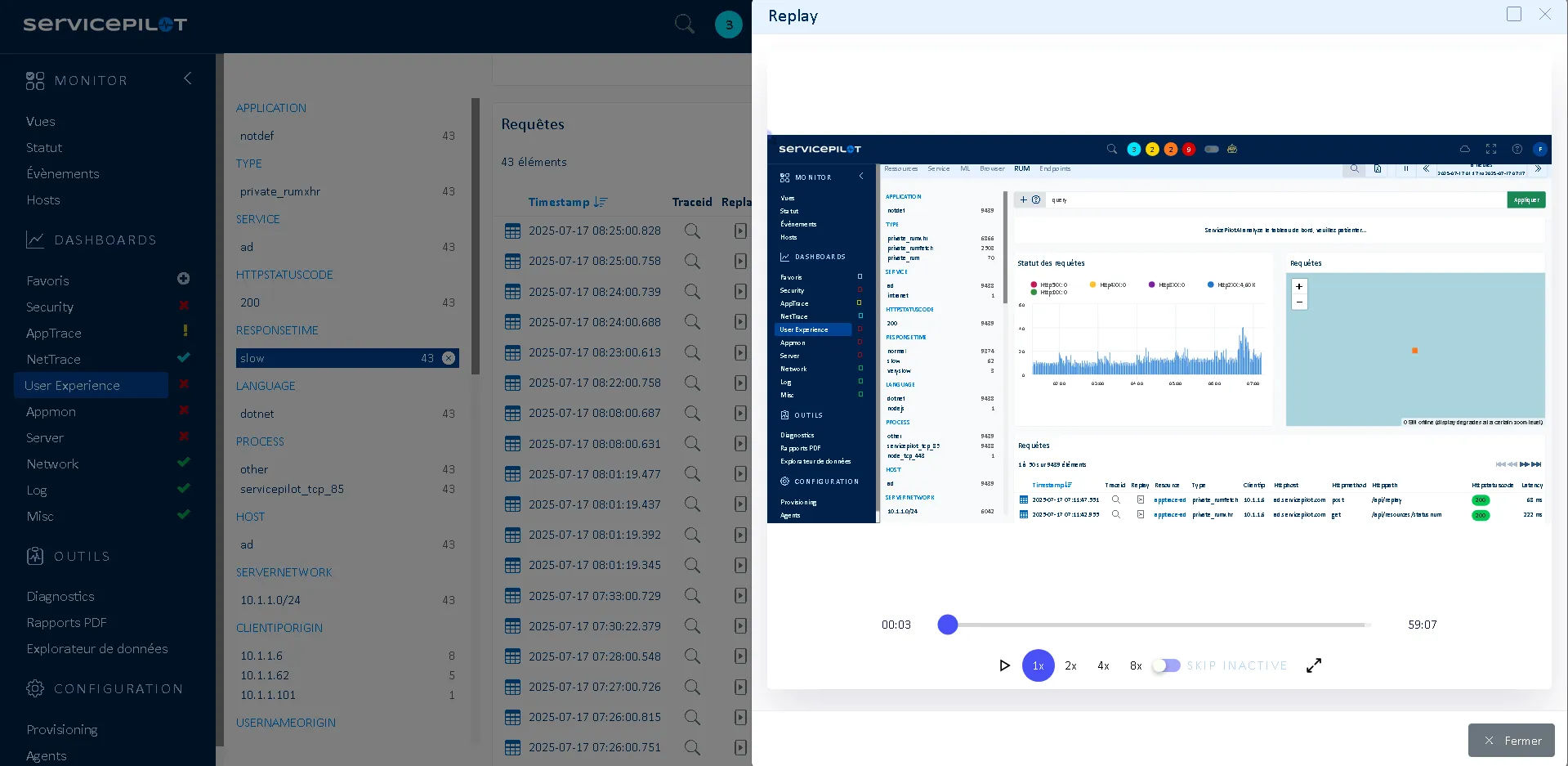
La funcionalidad Session Replay le permite grabar y reproducir las interacciones del usuario con su aplicación web como clics, movimientos del ratón, navegación y errores. Complementa el Real User Monitoring proporcionando un reproductor visual para el análisis del comportamiento de la experiencia del usuario.
Esto permite revisar la experiencia de un usuario y su recorrido para diagnosticar eficazmente problemas de usabilidad, rendimiento o bugs funcionales.
Recopilación de datos del RUM
Para recopilar métricas de Real User Monitoring (RUM) en sus páginas web, necesita integrar el script RUM de ServicePilot.
Dependiendo de su entorno, son posibles varios métodos de integración:
- Servidores de aplicaciones Java (Tomcat, Jetty). Utilice un plugin dedicado de ServicePilot para inyectar automáticamente el script RUM en las respuestas HTML generadas por sus aplicaciones. No es necesaria ninguna modificación manual del código. Esto permite una integración centralizada y transparente en entornos Web Java clásicos, basados en JSP, servlets o frameworks como Spring MVC.
- Servidores Web / Proxies (Apache, NGINX, IIS…). Configure sus servidores o proxies para modificar las páginas HTML servidas, inyectando dinámicamente el script RUM. Este método puede ser preferible cuando no puede modificar el código de la aplicación pero controla la capa de entrega web. Por ejemplo, IIS permite utilizar la extensión URL Rewrite con un módulo de inyección HTML.
- Páginas web estáticas o aplicaciones SPA. Añade manualmente el script RUM al código fuente de sus páginas web, idealmente en la sección <head> . Esto es adecuado para sitios HTML estáticos, Single Page Applications (React, Angular, Vue.js…) o integraciones CMS (WordPress, Drupal…). La inserción manual en el código también permite establecer una instrumentación de grano fino, página por página o condicionalmente, dependiendo del entorno.
¿Dónde obtener el script RUM?
Puede acceder a las instrucciones detalladas para la instrumentación RUM desde la interfaz de ServicePilot bajo la sección CONFIGURACIÓN en Parámetros > Reglas APM > Instrumentación RUM. Encontrará el script listo para usar, junto con opciones de configuración adaptadas a sus casos de uso específicos.
Activación del Session Replay
La opción del Session Replay puede activarse en la configuración del script JavaScript de RUM. Una vez actualizado el script y desplegado en las páginas objetivo, se recopilarán las sesiones de los usuarios de la aplicación supervisada.
Visualización de datos RUM y Session Replay
Los datos recopilados están disponibles en varias interfaces de ServicePilot, que ofrecen tanto cuadros de mando globales como interfaces específicas para diagnósticos contextualizados.
Los cuadros de mando estándar de ServicePilot RUM con vistas consolidadas o individuales están disponibles bajo la sección DASHBOARDS en User Experience > Rum.
Al consultar los Detalles de los consultas de RUM, la columna Replay muestra un icono cuando hay un Session Replay disponible.
Monitoring sintético
¿Qué es el monitoring sintético?
El monitoring sintético es una técnica de supervisión que simula una o varias acciones de usuario en un sitio web, independientemente del tráfico real. Probar páginas críticas o rutas de usuario a intervalos de tiempo regulares permite supervisar la disponibilidad, el rendimiento y el correcto funcionamiento de las aplicaciones de servicios Web.
Recopilación de datos del monitoring sintético
ServicePilot ofrece varios packages para implementar la supervisión sintética adaptada a sus necesidades:
ServicePilot webcheck - comprobación HTTP(S)
El package user-webcheck permite monitorear las respuestas de un servidor mediante una petición HTTP(S) emitida por un Agente de ServicePilot :
- Recoge código HTTP, tiempo de respuesta, información del certificado SSL.
- Soporta peticiones GET/POST, con encabezados personalizados, código HTTP esperado…
- Extrae datos numéricos de la página (por ejemplo, número de elementos, valor del contador).
Aunque aparentemente elemental, este package puede convertirse en una potente herramienta de supervisión cuando se implementa estratégicamente. Al multiplicar los puntos de prueba (mediante Agentes ServicePilot situados en diferentes zonas geográficas, detrás de proxies o en redes con latencia variable), es posible obtener una visión bastante real y distribuida de la experiencia del usuario.
ServicePilot web-scenario - escenarios multietapa
El package user-web-scenario monitorea los tiempos de respuesta del servidor a través de una serie de peticiones HTTP(S) emitidas por el Agente ServicePilot. Cada etapa del escenario puede personalizarse según sea necesario.
Todas las peticiones son ejecutadas por el Agente ServicePilot a intervalos regulares, proporcionando una supervisión continua del rendimiento.
Integración de pruebas funcionales externas
Para complementar los packages nativos, ServicePilot ofrece varios packages estándar para integrar los resultados de pruebas funcionales de herramientas de terceros. Estos resultados se pueden volver a introducir en ServicePilot en forma de informes con fecha y hora, enriqueciendo los cuadros de mando con datos de pruebas automatizadas.
| Software de terceros | Descripción | Packages de ServicePilot |
|---|---|---|
| Lighthouse | Herramienta de auditoría automatizada desarrollada por Google para evaluar el rendimiento, la accesibilidad, el SEO y las buenas prácticas de las páginas web. | Integración de Lighthouse |
| Puppeteer | Librería Node.js para automatizar un navegador Chrome o Chromium a través de una API de alto nivel, incluso en SPAs y sobre contenidos dinámicos. Permite emular escenarios complejos con navegación, clics, entradas, retardos y capturas de pantalla. | Integración de Puppeteer |
| NightWatchJS | Framework E2E basado en Node.js y Selenium. Ideal para validar flujos críticos con aserciones (presencia de texto, estado HTTP, campos completados, etc.). | Integración de NightWatchJS |
| Playwright | Solución cross-browser para pruebas en Chrome, Firefox y Safari. Admite pruebas paralelas, aserciones visuales e interacciones enriquecidas (drag & drop, uploads…). | Integración de Playwright |
| SikuliX | Utiliza el reconocimiento visual para automatizar interacciones basadas en la interfaz gráfica (UI). Muy útil cuando los elementos DOM son inaccesibles o dinámicos (ideal para aplicaciones heredadas o no HTML). | Integración de SikuliX |
Visualización de datos del monitoring sintético
ServicePilot ofrece cuadros de mando estándar, con vistas consolidadas o individuales de los datos bajo la sección DASHBOARDS en User Experience > Web-Scenario o WebCheck.
Los datos de Synthetic Monitoring de herramientas de terceros se centralizan en cuadros de mando dedicados bajo la sección DASHBOARDS en Appmon > [nombre del package].
Logs de aplicaciones
Los logs de aplicaciones, sistemas y seguridad son una fuente importante para diagnosticar incidentes en profundidad o enriquecer las alertas con contexto. En un enfoque moderno de observabilidad, los logs complementan las trazas de aplicaciones, las métricas y las pruebas sintéticas.
ServicePilot admite la importación de los principales formatos de registros, lo que le permite recopilar y normalizar datos de diversas aplicaciones e infraestructuras sin problemas. Tanto si los registros se generan en formato de servidor web IIS W3C, como en flujos Syslog tradicionales, los Windows Events en entornos de Microsoft u otros estándares habituales, ServicePilot los unifica en un flujo de análisis coherente. Esta flexibilidad garantiza que los equipos puedan supervisar, correlacionar y analizar eventos en entornos heterogéneos.
Entre todos los distintos formatos de registros (W3C, Syslog, registros de eventos de Windows, CEF, LEEF, etc.), los principales tipos de registros pueden clasificarse en una serie de categorías funcionales. Estas categorías describen lo que representan los registros, independientemente de su formato.
| Tipo de logs | Descripción |
|---|---|
| Logs de acceso | Registran quién ha accedido a un servicio, cuándo, desde dónde y cómo. Son habituales en los formatos W3C, CLF, JSON y en los registros de proxy. |
| Logs de eventos | Capturan eventos del sistema o de la aplicación, como el inicio de servicios, cambios de configuración o advertencias. Son típicos en Syslog y en los registros de eventos de Windows. |
| Logs de errores | Informan de fallos, excepciones, bloqueos y comportamientos inesperados. Están presentes en casi todos los formatos. |
| Logs de seguridad | Autenticación, autorización, eventos de cortafuegos, intentos de intrusión. A menudo se estructuran en CEF, LEEF, Syslog y los registros de seguridad de Windows. |
| Logs de auditoría | Realizan un seguimiento de las acciones administrativas, los cambios de configuración y las operaciones relevantes para el cumplimiento normativo. Son habituales en los registros de la nube, los registros de bases de datos y los registros de eventos de Windows. |
| Logs de transacciones | Representan operaciones empresariales o de bases de datos (pagos, escrituras de datos, confirmaciones). Se encuentran en registros JSON, registros de bases de datos y formatos específicos de aplicaciones. |
| Logs de rendimiento | Métricas, latencia, rendimiento y uso de recursos. A menudo se generan en formato JSON o Syslog estructurado. |
| Logs de debug | Información interna muy detallada para la resolución de problemas. Son habituales en formato JSON y en formatos específicos de aplicaciones. |
Centralizar los logs en ServicePilot le permite :
- Buscar rápidamente los logs de su sistema o aplicación
- Correlacionar los logs con las trazas de red, alertas y eventos
- Disponer de un historial detallado de cada evento técnico para auditorías, diagnósticos o análisis de comportamientos anómalos
Recopilación de logs en W3C
ServicePilot admite la ingesta de logs en formato W3C, utilizado en particular por servidores web de IIS o load balancers y proxies. Estos logs pueden incluir información sobre solicitudes HTTP, estado, tiempos de procesamiento y direcciones IP de origen. Si el sitio ya está instrumentado con RUM, los logs W3C pueden mejorarse con encabezados de solicitud personalizados para mejorar el seguimiento de los usuarios.
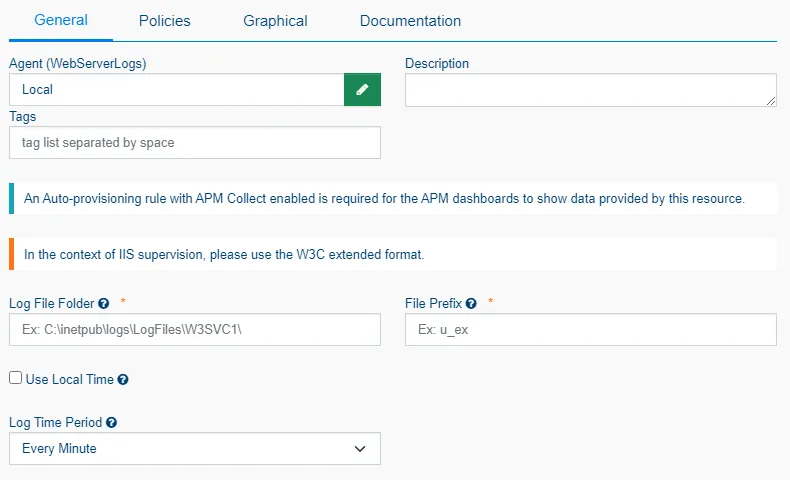
El package apptrace-appservice-w3c está diseñado para recopilar automáticamente los logs W3C presentes en el servidor web como IIS o Apache, según una ruta definida durante la configuración.
En particular, permite :
- Ver las solicitudes HTTP entrantes.
- Analizar los tiempos de respuesta.
- Identificar errores de aplicación (códigos 4xx/5xx).
Visualización de datos de los logs W3C
Los cuadros de mando estándar de los logs W3C están disponibles con vistas consolidadas o individuales en la sección DASHBOARDS en AppTrace > appservice-w3c.
Más interfaces permiten una exploración granular de las consultas en la sección DASHBOARDS en AppTrace > Aplicacionesm AppTrace > Consultas o AppTrace > L7 Map.
