Gestión de problemas y análisis de causas raíz
¿Qué es la fatiga de alertas?
La fatiga de alertas es el fenómeno por el cual un volumen excesivo de alertas (a menudo falsos positivos o de baja prioridad) desensibiliza a los equipos de supervisión, lo que provoca que se ignoren las alertas, se retrasen las respuestas o se pasen por alto incidentes. Esto ocurre cuando los operadores se ven sobrecargados por notificaciones repetidas y poco relevantes emitidas por herramientas de supervisión o seguridad. El resultado es una disminución de la vigilancia y un aumento del riesgo de error humano.
¿Cómo ocurre esto?
- Demasiadas alertas simultáneas o frecuentes
- Falsos positivos y alertas de baja prioridad sin filtrar
- Falta de priorización y de escalado claro en los procedimientos operativos
Estos factores conducen a la desensibilización y a respuestas lentas a las alertas realmente críticas. Las consecuencias concretas para las organizaciones son:
- Alertas críticas perdidas y mayores tiempos de resolución
- Desánimo y desmoralización de los equipos de supervisión
- Mayor riesgo operativo y de seguridad
Reducir el MTTR y la fatiga de las alertas en sistemas de información
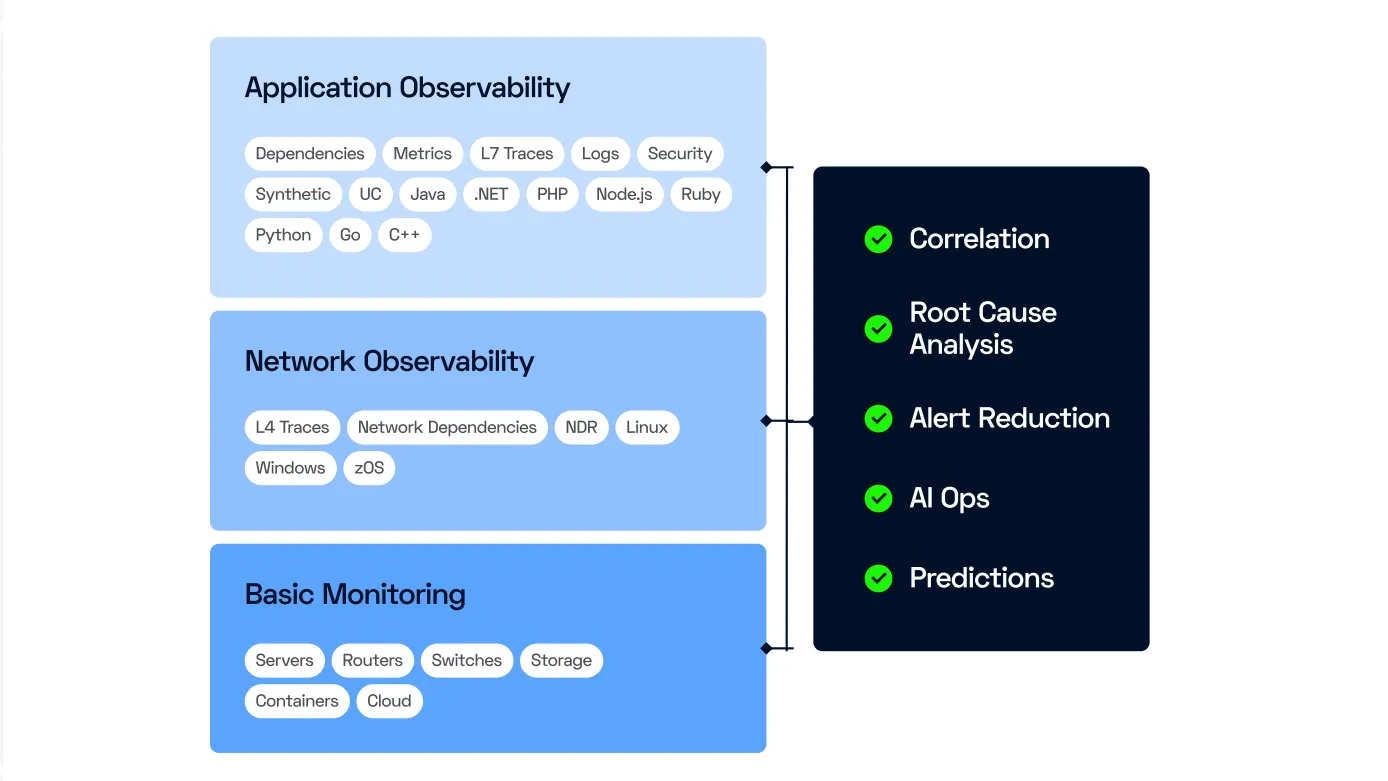
En los entornos modernos con aplicaciones basadas en arquitecturas de tipo microservicios e infraestructuras distribuidas híbridas o alojadas en la nube, la gestión eficaz de los problemas y el análisis de las causas profundas (RCA) son fundamentales.
Estas arquitecturas complejas requieren una supervisión exhaustiva para identificar rápidamente los incidentes y sus causas subyacentes. Esto permite evitar incidentes en cadena, minimizar el tiempo de inactividad y garantizar un rendimiento óptimo.
Por eso, ServicePilot v12 introduce un nuevo concepto de "Problemas" que mejora la gestión de incidentes y el análisis de las causas profundas. Esta función permite correlacionar de forma inteligente las alarmas e identificar las causas raíz con mayor precisión.
Conceptos fundamentales: incidente, anomalía, problema, causa raíz
Un incidente aparente (por ejemplo, un servicio lento) puede ser la consecuencia de un problema más profundo (infraestructura, dependencia, base de datos, error de aplicación, etc.). Sin una correlación inteligente, se corre el riesgo de una avalancha de alertas redundantes ("fatiga de alertas"), con un aumento del ruido que en realidad es perjudicial. La idea es agrupar lo que pertenece al mismo "problema".
Incidente/Alerta: cualquier comportamiento observable que tenga umbrales (lentitud, error, saturación, bloqueo, etc.). Cuando se identifica un incidente significativo, se marca con un estado crítico o no disponible en ServicePilot. Un estado crítico indica un rendimiento significativamente degradado, mientras que un estado no disponible indica un fallo.
Anomalía: una anomalía en las alertas de supervisión es un evento o comportamiento que se desvía del funcionamiento o comportamiento normal esperado de un sistema.
Problema: entidad lógica que agrupa varios incidentes anómalos que comparten una misma causa raíz para agrupar los síntomas y evitar alertas duplicadas.
Análisis de la causa raíz (RCA): proceso destinado a identificar la causa subyacente a partir de los eventos y el contexto, y no solo de los síntomas visibles durante un incidente.
Principios del análisis automático y la correlación
Datos utilizados para agrupar y deduplicar las alertas
Los algoritmos avanzados de ServicePilot utilizan múltiples datos (métricas, trazas, flujos, eventos) a todos los niveles (infraestructuras, servicios, aplicaciones). La topología del entorno es fundamental para la correlación, ya que permite analizar correctamente las dependencias entre servicios, procesos, hosts, contenedores, etc.
Para evitar alertas redundantes y simplificar la gestión de incidentes, se utilizan varios criterios de agrupación y deduplicación:
- Dependencias L4: las dependencias del nivel 4 (capa de transporte) se tienen en cuenta para agrupar los incidentes relacionados con conexiones de red específicas
- Dependencias L7: las dependencias del nivel 7 (capa de aplicación) permiten agrupar los incidentes basados en protocolos de aplicación y servicios web
- Mismo host: los incidentes que afectan al mismo host se agrupan para su gestión centralizada.
- Misma LAN: los incidentes que se producen en la misma red local (LAN) también se agrupan para un análisis más eficaz.
Correlación contextual, temporal y algorítmica
El análisis no se limita a una simple activación simultánea (marca de tiempo). Combina el contexto (dependencias, topología, llamadas, transacciones) y los datos históricos para evitar falsos positivos o conclusiones erróneas.
Por ejemplo, si un servicio A se ralentiza y luego un servicio B se ralentiza, el motor debe determinar si esa es la causa o si se trata de otro problema (no solo "B es lento porque A lo era").
El enfoque se basa en lo que se denomina "análisis de árbol de fallos": a partir de las dependencias conocidas, la IA remonta el árbol de causalidad para identificar la posible fuente raíz.
El resultado: un "problema" único que agrupa todos los eventos relacionados con la misma causa, con una entidad raíz identificada, lo que evita duplicados o alertas múltiples para una misma causa.
Ciclo de vida de un "problema": desde la detección hasta la resolución
La duración de un problema en ServicePilot se gestiona de forma dinámica para garantizar una respuesta rápida y eficaz:
-
Detección de un primer evento anormal provoca la creación de un "problema" por parte de la IA. Se crea automáticamente un problema si una anomalía persiste durante al menos 3 minutos. Esto garantiza que las alertas no se activen por fluctuaciones temporales.
-
Periodo de análisis y correlación: el motor de ServicePilot recopila los eventos asociados, amplía el contexto (topología, dependencias, trazas) y encuentra la causa raíz.
-
Actualización del "feed de problemas" en tiempo real: los nuevos eventos relacionados se agregan al mismo problema si tienen la misma causa. La adición dinámica permite añadir eventos relacionados posteriormente para proporcionar una visión completa y contextual del incidente durante un periodo máximo de 90 minutos después de la creación del problema.
-
El cierre automático del problema se produce cuando todas las entidades afectadas vuelven a la normalidad, con la posibilidad de reabrirse automáticamente si los síntomas reaparecen en un plazo de 30 minutos (reopening window).
Valor añadido para los equipos DevOps / SRE / IT
Al utilizar las nuevas alertas de problemas, las ventajas para los equipos de supervisión son numerosas:
- Mejor priorización y clasificación: al combinar el impacto, la causa raíz y el contexto, los equipos pueden decidir qué debe tratarse con prioridad.
- Menos "ruido" de alertas: al agrupar varios eventos en un solo problema, se evita la sobrecarga de alertas redundantes por la misma causa.
- Análisis en profundidad (infraestructuras, aplicaciones, bases de datos, dependencias): es posible identificar causas profundas complejas (por ejemplo memoria, Garbage Collector, consultas de bases de datos, contenedores, infraestructura, etc.).
- Reducción del MTTR (tiempo medio de reparación): la automatización y la correlación reducen el tiempo dedicado al diagnóstico.
La nueva funcionalidad de ServicePilot v12 transforma los ruidosos flujos de alertas en problemas sobre los que se puede actuar, identifica con precisión las causas raíz y orienta a los equipos hacia las acciones de mayor impacto, lo que supone una palanca concreta para mejorar la fiabilidad de los sistemas distribuidos y acelerar la resolución de incidentes.
