Alertas
ServicePilot puede alertar a los usuarios tan pronto como se produce un evento importante. También puede generar proactivamente alertas si es probable que una tendencia supere un umbral en el futuro. También se pueden retener las alertas si se espera que un evento se disipe sin ninguna acción.
Por defecto, ServicePilot presentará todos los datos a través de su interfaz web, pero no se generarán alertas. Para añadir alertas, se deben configurar nuevas Policies de Alerta. Tenga en cuenta que las Policies de Alerta son todas independientes entre sí. Hay que tener cuidado al crear nuevas alertas para evitar generar alertas superpuestas que puedan alertar a los usuarios del mismo problema repetidamente.
Para agregar Policies de Alerta, ver la documentación Policies.
Cada alerta tiene tres componentes :
- Una Condición define lo que activará la alerta
- Un Retraso indica si la alerta debe retrasarse durante un cierto tiempo o una serie de eventos similares
- Se toma una Acción cuando se cumplen las condiciones de alerta y el límite de tiempo ha expirado
Condición de alerta
Para que se active una alerta, deben cumplirse ciertas condiciones. Estas condiciones están asociadas a los eventos que ServicePilot detecta.
| Tipo de condición | Evento |
|---|---|
| Recursos | Cambiar el estado de un recurso dentro de un período de tiempo definido. |
| Objetos | Cambiar el estado de un objeto dentro de un período definido. Los objetos que desencadenan la alerta pueden filtrarse por nombre, clase, vista y estado de reconocimiento. |
| Query | Una consulta Lucene y un umbral se ejecutan cada minuto. |
| Vistas | Cambiar el estado de una vista durante un período de tiempo definido. Las vistas que desencadenan la alerta pueden filtrarse por nombre, clase y estado de reconocimiento. |
| Indicadores | Cambiar el estado de un indicador individual dentro de un período definido. Los indicadores que activan la alerta pueden filtrarse por nombre, nombre del objeto, clase de objeto, vista y estado de reconocimiento. |
| NDR | Se ha detectado un evento de Detección y Respuesta de Red (NDR). |
| SNMP Trap | Recepción por ServicePilot de una trap o notificación SNMP durante un período de tiempo definido. Las trampas pueden ser categorizadas usando las reglas de categorización de SNMP Trap antes de ser filtradas por nombre de la regla, categoría de la regla, mensaje de la regla, severidad de la regla, OID corporativo, tipos genéricos y específicos, direcciones IP del remitente y del agente. Nota que si un Trap es descartado y por lo tanto no se almacena en la base de datos de ServicePilot, la Policy de Alerta no se aplicará. |
| Syslog | Recibiendo un mensaje del syslog en un período de tiempo definido. Los Syslogs pueden filtrarse por dirección IP de origen, gravedad, instalación, host, descripción, etiqueta, PID, ID de Msg y datos. |
Nota: los operadores pueden marcar los estados de alerta de los recursos, vistas y objetos como reconocidos. Los elementos reconocidos pueden entonces incluirse o excluirse de las condiciones de alerta y de la sección de “estado” de la supervisión.
Nota: La casilla de selección “Recursos con al menos un objeto en estado anómalo”, situada en la sección Condición de los “Objetos”, permite aplicar una policy únicamente a los eventos basados en anomalías. Filtra las alertas generadas por umbrales estáticos y activa acciones solo cuando el análisis histórico determina que el estado del recurso del objeto es anómalo.
Condición Ack
Cuando se crean Policies de Alerta con condiciones de Objetos, Vistas o Indicadores, el campo Ack puede ser configurado para incluir o excluir eventos adquiridos. Hay tres opciones para el campo Ack:
| Ack | Utilización |
|---|---|
| Ignore | Ignora el estado Ack del artículo. |
| Ack | Incluya sólo aquellos elementos que tengan problemas de rendimiento o disponibilidad que ya hayan sido reconocidos. |
| Not Ack | Incluya sólo los elementos que aún no han sido reconocidos. |
Retraso de la alerta
Aunque todas las condiciones de una alerta pueden ser satisfechas, la acción de alerta no se ejecutará hasta que el retraso haya expirado:
| Tipo de retraso | Utilice |
|---|---|
| Sin demora | Se tomarán medidas tan pronto como se cumplan las condiciones. |
| Acción e ignorar condición para x Minutos | Se tomarán medidas tan pronto como se cumplan las condiciones. Sin embargo, la acción ya no se llevará a cabo durante la duración especificada, incluso si las condiciones se cumplen de nuevo. Esta opción es útil cuando es probable que las condiciones se produzcan repetidamente y sólo se quiera ser alertado una vez. |
| Acción después de x minutos si la condición sigue siendo verdadera | La acción se retrasará por la duración especificada. Sólo si las condiciones siguen siendo verdaderas después de este retraso, la acción tendrá lugar. Esta opción es útil cuando pueden darse condiciones y luego recuperarse por sí mismas. Si el problema persiste, se desencadenará la acción. |
| Acción después de x casos de la Condición durante y minutos | La acción sólo se desencadenará si se produce un número de veces durante la duración especificada. Esta opción es útil para eventos como los intentos fallidos de ingreso, recibidos por el syslog, que indicarían un intento de violación de la seguridad. |
Acción de alerta
Una vez que se han cumplido las condiciones, y que ha expirado cualquier límite de tiempo, se pueden tomar varias medidas.
| Tipo de condición | Evento |
|---|---|
| Enviar un correo electrónico. | |
| Webhook | Enviar una solicitud web GET o POST. Esto permite la integración con sistemas de tickets o plataformas de mensajería como Microsoft Teams. Consulte los ejemplos para obtener más información. |
| UDP | Enviar un paquete UDP. Si el paquete UDP está correctamente formateado y enviado al puerto correcto, esto puede ser definido como un mensaje Syslog. |
| Trap | Enviar un Trap SNMP. |
Note: por defecto, las acciones Email agrupan todas las alertas del mismo tipo cada minuto y envían un email de resumen con todos los cambios. Para enviar correos electrónicos individuales por alerta, seleccione la opción No agrupado y especifique el asunto del correo electrónico y el texto del cuerpo que desea utilizar.
Variables de alerta
Cuando se dispara una alerta, cierta información se almacena en variables y puede utilizarse en la acción de alerta. Por ejemplo, en el asunto de un correo electrónico puede figurar el nombre del asunto que ha disparado la alerta, o un mensaje del syslog UDP puede indicar la hora en que se produjo el evento.
Algunas variables son comunes a todas las condiciones de alerta, mientras que otras variables difieren según las condiciones utilizadas. Por ejemplo, si se necesita el valor del indicador que ha superado su umbral, sólo estará disponible para las alertas con una condición del tipo Indicadores.
Variables comunes
Se recoge información común para todas las alertas.
| Variable | Contenido |
|---|---|
{DATE} |
La fecha de alerta se basa en la hora local en el servidor de ServicePilot |
{TIME} |
La hora de alerta se basa en la hora local del servidor de ServicePilot |
{DATEUTC} |
Fecha de alerta en UTC |
{TIMEUTC} |
Hora de alerta en UTC |
{BASEURL} |
URL base del servidor ServicePilot |
{LOCALIP} |
Dirección IP del servidor ServicePilot |
{LOCALWEBPORT} |
Puerto web del servidor ServicePilot |
Las variables basadas en la condicións
Estas variables sólo están disponibles dependiendo de la condición de la política de alerta.
| Condición | Variable | Contenido |
|---|---|---|
| Recursos, Vistas, Objetos, Indicadores | {RESOURCE} |
El nombre del recurso |
{PACKAGE} |
El tipo de package del recurso | |
{TECHNOLOGY} |
Tipo de package o primera parte del nombre del package | |
{TAGS} |
Todos los valores de tags asociados al recurso | |
{TAG_1} ... {TAG_5} |
Del primero al quinto valor de tag asociado al recurso | |
{STATUS} |
El estado actual del recurso, vista u objeto como un personaje único (?, -, 1, 2, 3, +) | |
{STATUSBADGE} |
El estado actual del recurso, vista u objeto como texto con formato HTML (?,-,1,2,3,+) | |
{STRSTATUS} |
El estado actual del recurso, vista u objeto como texto (UNKNOWN, UNAVAILABLE, MINOR, MAJOR, CRITICAL, OK) | |
{OLDSTATUS} |
El estado previo del recurso, vista u objeto como un personaje único (?, -, 1, 2, 3, +) | |
{OLDSTATUSBADGE} |
El estado anterior del recurso, vista u objeto como texto con formato HTML (?,-,1,2,3,+) | |
{STROLDSTATUS} |
El estado previo del recurso, vista u objeto como texto (UNKNOWN, UNAVAILABLE, MINOR, MAJOR, CRITICAL, OK) | |
{DURATION} |
El tiempo que la vista o el objeto ha estado en el estado actual | |
{PROBLEMNOTE} |
Una nota relacionada con el problema, introducida por un operador | |
{TEXT} |
Un texto que explica el último cambio de estado de una vista o un objeto | |
{DESCRIPTION} |
Contenido del campo de descripción del recurso | |
{NOTE} |
El contenido del campo Nota | |
| Vistas, Objetos, Indicadores | {CLASS} |
El tipo de vista u objeto |
{VIEW} |
El nombre de la vista | |
{PARENTVIEW} |
La vista relativa de la que disparó la alerta | |
{OBJECT_1} ... {OBJECT_5} |
Ver las constantes de contenido u objeto 1 a 5 | |
{VIEW_0} ... {VIEW_9} |
El nombre de las vistas de nivel 0 a 9 en las que se encuentra esta vista, 0 corresponde a la vista MAIN | |
| Recursos, Objetos, Indicadores | {ANOMALY} |
Si esta alerta se basa en una anomalía detectada, entonces se devuelve ! en este campo. Si HTML está activado, este campo incluirá formato HTML |
| Objetos, Indicadores | {OBJ} |
El nombre del objeto |
{IP} |
La dirección IP del objeto | |
{HOST} |
El FQDN o la dirección IP del objeto, dependiendo de los métodos de resolución de nombres disponibles | |
{AGENTNAME} |
Nombre del Agente ServicePilot que proporciona datos al objeto | |
| Indicadores | {INDICATORSTATUS} |
La situación actual del indicador como un solo carácter (?, -, 1, 2, 3, +) |
{INDICATOROLDSTATUS} |
La situación anterior del indicador como un solo carácter (?,-,1,2,3,+) | |
{INDICATORNAME} |
El nombre del indicador | |
{INDICATORVALUE} |
El valor actual del indicador | |
| Syslog | {TIMESTAMP} |
La marca de tiempo que se encuentra en el syslog |
{IP} |
La dirección IP desde la que se recibió el syslog | |
{HOST} |
El huésped encontrado en el syslog | |
{PID} |
La PID que se encuentra en el syslog | |
{TAG} |
La Tag que se encuentra en el syslog | |
{TEXT} |
El texto del syslog | |
{DESCRIPTION} |
El texto del syslog después de que todos los elementos nombrados hayan sido analizados | |
{FACILITY} |
Syslog Facility | |
{SEVERITY} |
Gravedad del syslog | |
{MSGID} |
El ID del mensaje encontrado en el syslog | |
{DATA} |
Los datos estructurados que se encuentran en el syslog | |
| SNMP Trap | {TRAPNAME} |
El nombre de la regla de la trap |
{TRAPCATEGORY} |
La categoría asociada a la regla de la trap | |
{TRAPSEVERITY} |
La gravedad asociada con la regla de la trap | |
{TRAPMESSAGE} |
El mensaje asociado a la regla de la trap | |
{TRAPIPSENDER} |
La dirección IP del remitente de la trap | |
{TRAPIPAGENT} |
La dirección IP del agente SNMP que envió la trap | |
{TRAPALLOIDVALUES} |
El conjunto de valores OID de la trap recibida | |
{TRAPOID1} ... {TRAPOID20} |
El nombre de la variable OID de la trap de 1 a 20 | |
{TRAPVALUE1} ... {TRAPVALUE20} |
El valor de la trap OID variable de 1 a 20 | |
| NDR | {TIMESTAMP} |
Hora a la que se detectó el evento NDR |
{PROTO} |
El protocolo (TCP, UDP, ICMP) del evento NDR | |
{SRCAGENT} |
El Agente ServicePilot que detecta el origen del tráfico de eventos NDR | |
{SRCIP} |
Dirección IP de origen del tráfico de eventos NDR | |
{SRCHOST} |
El nombre del host de origen del tráfico de eventos NDR | |
{SRCCOUNTRY} |
País de origen del tráfico de eventos NDR | |
{SRCPROCESS} |
ID del proceso de origen del tráfico de eventos NDR | |
{DSTAGENT} |
El Agente ServicePilot detecta el destino del tráfico de eventos NDR | |
{DSTIP} |
Dirección IP de destino del tráfico de eventos NDR | |
{DSTPORT} |
Puerto de destino del tráfico de eventos NDR | |
{DSTHOST} |
Nombre del host de destino del tráfico de eventos NDR | |
{DSTCOUNTRY} |
País de destino del tráfico de eventos NDR | |
{DSTPROCESS} |
ID del proceso de destino del tráfico de eventos NDR | |
{MODEL} |
El modelo que desencadena el evento NDR | |
{ATTACK} |
El tipo de ataque detectado por el modelo | |
{SCORE} |
La puntuación de certidumbre del acontecimiento NDR | |
| Query | {COLLECTION} |
La recopilación de datos de ServicePilot consultó |
{QUERY} |
La consulta Lucene realizada | |
{OPERATOR} |
El operador de umbral utilizado para comparar la consulta con el umbral | |
{THRESHOLD} |
El valor umbral utilizado para comprobar la consulta | |
{VALUE} |
El valor devuelto por la consulta | |
| Retardo no “No retraso” | {CORRID} |
El ID de correlación único para el contexto de la alerta que se utilizó para comprobar las condiciones después del tiempo especificado |
{WINDOW} |
La ventana de tiempo durante cual se verificaron las condiciones de la alerta, lo que desencadenó la alerta | |
{NBEVENTS} |
El número de eventos que coinciden con las condiciones de la alerta que la activan |
Reconocer los cambios de estado
Cuando los elementos en el ServicePilot cambian de estado a no disponible o tienen un problema de rendimiento, los objetos, vistas y recursos reflejarán este problema. Es posible conocer el problema para que pueda ser ignorado en las vistas de Estado y las condiciones de alerta. Reconocer un problema no cambiará su estado ni ocultará el problema, pero una nota será visible junto al elemento reconocido.
Si el problema se resuelve y los elementos se vuelven disponibles y nominales, el reconocimiento desaparecerá. Esto puede ser un problema para los elementos que cambian continuamente entre el estado nominal y el estado malo, ya que no se mantendrá un reconocimiento. En este caso, se puede añadir una Nota en su lugar, ya que no se eliminará automáticamente.
Accediendo a “Ack/Note” de un objeto desde el mapa
- Como usuario con al menos privilegios de operador, navega en la jerarquía de la Vista hasta el objeto que desees reconocer/apuntar y haz clic en él.
- Haga clic en el botón Ack o Note
Accede a “Ack/Note” de la vista desde el mapa
- Como usuario con al menos privilegios de operador, navegue en la jerarquía de la Vista a la vista que desee reconocer/anotar.
- Haga clic en el icono Lupa.

- Haga clic en el botón Ack o Note.
Acceder a “Ack/Note” desde las listas de estado
- Como un usuario con privilegios de operador, navega a Estado.
- Seleccione Recurso, Objeto o Vista en el sub-menú Estado dependiendo del componente que desee reconocer/anotar.
- Seleccione uno o más elementos para salir o notar y haga clic en el botón ack verde o en el botón note azul.
Filtrar listas de estado
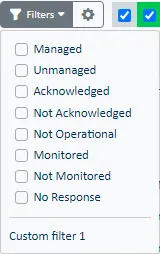
En las listas de estado, puede encontrar elementos según una serie de criterios de filtrado. La lista de filtros disponibles depende de la lista de estados (Recurso, Objeto, Vista) seleccionada:
| Filtro | Definición |
|---|---|
| Managed | Mostrar los elementos que no están marcados como no gestionados. Los operadores pueden marcar manualmente los elementos como no gestionados para dejar de informar sobre su estado o también dejar de recopilar datos. |
| Unmanaged | Ver los elementos que actualmente están marcados como no gestionados. Los operadores pueden marcar manualmente los elementos como no gestionados para dejar de informar sobre su estado o también dejar de recopilar datos. |
| Acknowledged | Muestra los elementos que tienen problemas de rendimiento o disponibilidad y que han sido marcados con un Ack. |
| Not Acknowledged | Mostrar los elementos que no han sido marcados con un Ack. |
| Not Operational | Mostrar elementos parpadeantes, indicando que un Agente ServicePilot no está reportando ciertos datos para el recurso. |
Ejemplos de alerta
Recibir un e-mail cuando un Ping no responde
Para recibir un e-mail cuando un ping ya no responde, se requiere una Policy de tipo Alerta:
- Añade una nueva Policy de tipo Alerta.
- Definir un nombre de la Policy de alerta correspondiente. Por ejemplo:
alert_ping_no_response_email. - Marque la casilla Aplicar esta Policy a toda la configuración para que la Policy se aplique a todos los objetos
Pingde la configuración. - En la pestaña de Condición, establezca la clase de condición en Objetos.
- Poner De status en todos los colores excepto en el rojo.
- Ponga el A status sólo en rojo.
- Poner Clases filtradas a
Ping. - En la pestaña Acción, establezca el tipo de acción en email.
- Definir las direcciones del remitente y del destinatario (separadas por un punto y coma).
- Si decide enviar mensajes de correo electrónico no agrupados, marque la casilla No agrupados.
- Si decide enviar mensajes de correo electrónico no agrupados, define el Tema. Por ejemplo:
(ServicePilot) El ping de {OBJ} ya no responde. - Si decide enviar mensajes de correo electrónico no agrupados, ponga el Mensaje. Por ejemplo:
El Ping de {OBJ} no responde a {DATE} {TIME}. - Guarda la nueva Policy.
Esta alerta puede ser enviada sólo para una parte de la configuración. Puede aplicar esta “Política” a una vista o a varios recursos individualmente.
Enviar una alerta como mensaje de canal de Microsoft Teams
Teams puede recibir y enviar mensajes a un canal utilizando una URL creada para enviar webhooks. Empiece por crear la URL en Microsoft Teams y, a continuación, configure la URL y el cuerpo POST correctamente en una alerta de ServicePilot.
- Añade una nueva Policy de tipo Alerta.
- Definir un nombre de la Policy de alerta correspondiente. Por ejemplo:
alert_teams_channel. - Establezca la Condición requerida.
- En la pestaña Action, establecer el tipo de acción a Webhook.
- Establezca el Método como Post.
- Establece los datos del Webhook usando una definición JSON de AdaptiveCard.
- Probar el nuevo Webhook.
- Guardar la nueva Policy de Alerta.
{
"type": "message",
"attachments": [{
"contentType": "application/vnd.microsoft.card.adaptive",
"contentUrl": null,
"content": {
"$schema": "http://adaptivecards.io/schemas/adaptive-card.json",
"type": "AdaptiveCard",
"version": "1.2",
"body": [{
"type": "TextBlock",
"text": "ServicePilot object unavailable: {OBJ}"
}
]
}
}
]
}
Alerta cuando una unidad de disco duro supera un umbral de uso
Para obtener notificaciones cuando el volumen de un disco duro excede el umbral de uso de espacio mayor o crítico, se debe agregar una nueva Policy del tipo Alerta:
- Añade una nueva Policy de tipo Alerta.
- Definir un nombre de la Policy de alerta correspondiente. Por ejemplo:
alert_disk_space_usage_high. - Marque la casilla Aplicar esta Policy a toda la configuración para que la Policy se aplique a todos los objetos
Server Diskde la configuración. - En la pestaña de Condición, establezca la clase de condición en Indicadores.
- Poner De status a gris, verde y azul.
- Ponga el A status en amarillo y naranja.
- Ponga las Clases filtradas en
Server Disk. - Ponga los Indicadore filtrado en
Space Usage. - Guardar la nueva Policy de Alerta.
Cuando la condición se establece en el tipo Indicadores, el nombre del indicador y los valores actuales pueden ser utilizados en la acción. Por ejemplo: Alerta {STRSTATUS} en el disco: El uso de {OBJ} está en {INDICATORVALUE}
Enviar Syslog cuando un objeto se convierte en crítico
Envía un mensaje syslog con formato RFC5424 cuando un objeto se vuelve crítico.
- Añade una nueva Policy de tipo Alerta.
- Establezca el nombre de la política de alerta de forma adecuada. Por ejemplo:
alert_object_critical. - En la pestaña de Condición, establezca De status en todos los marcados excepto críticos y A status en todos los no marcados excepto críticos.
- En la pestaña Acción, establezca el Tipo de acción en UDP.
- Establezca El puerto UDP en
514. - Establezca el Mensaje UDP como
<10>1 {DATEUTC}T{TIMEUTC}Z servicepilot.company.com servicepilot - - [criticalObjAlert@23098 object="{OBJ}" class="{CLASS}" problem="{PROBLEMNOTE}"] Critical Object Alert for {OBJ}, Problem: {PROBLEMNOTE}. - Guardar la nueva Policy de Alerta.
Alerta en caso de indisponibilidad de los recursos de un sitio fuera de las horas de oficina
Para obtener una alerta de fuera de horario, empieza por crear un período que defina los intervalos de tiempo fuera de horario. Entonces incluye este período en el nueva Policy de tipo Alerta:
- Añade un nuevo Período de tiempo con un nombre como
Después de la hora 1. - Definir los Intervalos para
00:00 - 09:00y18:00 - 23:59deLunesyViernes. - Guarda el nuevo Período.
- Añade un segundo Período de tiempo con un nombre como
Después de la hora 2. - Definir los Intervalos para
00:00 - 23:59paraSábadoetDomingo. - Guarda el nuevo Período.
- Añade una nueva Policy de tipo Alerta.
- Definir un nombre de la Policy de alerta. Por ejemplo:
alerte_ooh_site_ressource_non_disponible. - En la pestaña Condición, establezca la clase de condición en Recursos.
- Ponga el Período de Alerta en
Después de la hora 1|Después de la hora 2. - Poner De status en todos los colores excepto en el rojo.
- Ponga el A status sólo en rojo.
- Definir la acción.
- Guarda la nueva Policy.
- Aplicar la nueva Policy en la vista
Sitespara asignar todos los recursos contenidos en esa vista y sus sub-vistas.
