Las métricas de DevOps y SRE: Golden Signals, USE y RED
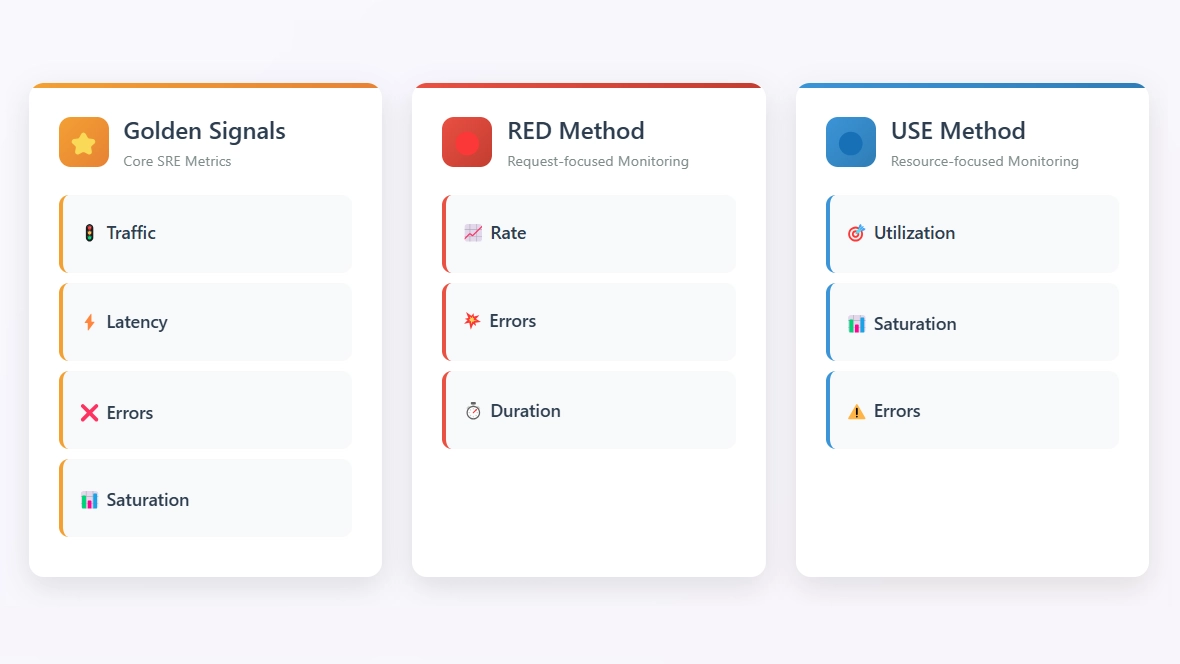
Métricas esenciales de DevOps y SRE: Golden Signals, USE y RED
La observabilidad moderna ya no se limita a recopilar métricas: consiste en modelar el comportamiento de un sistema, detectar desviaciones y correlacionar las señales para reducir drásticamente el MTTR. Los equipos de DevOps y SRE deben basarse en métricas fiables, procesables y estandarizadas para garantizar el rendimiento, la disponibilidad y la experiencia del usuario.
Ahí es donde entran en juego los marcos Golden Signals, USE y RED. Cada uno de ellos aporta un enfoque complementario para analizar el estado de un sistema. Combinados con una plataforma de observabilidad como ServicePilot, se convierten en una poderosa herramienta para controlar la complejidad.
⭐ Golden Signals: la base del SRE para supervisar los servicios
Las Golden Signals están diseñadas para medir el impacto directo en el usuario final. Fueron popularizadas por Google SRE y definen cuatro métricas esenciales para cualquier servicio distribuido (latencia, tráfico, errores y saturación).
Latencia: tiempo de respuesta percibido por el usuario
La latencia corresponde al tiempo necesario para procesar una solicitud de principio a fin. Es el tiempo de respuesta global del servicio, tal y como lo percibe el usuario.
Es fundamental distinguir la latencia de las solicitudes exitosas de la de las fallidas. En ocasiones, un error HTTP 500 puede devolverse muy rápidamente, por ejemplo, cuando un servicio de backend crítico no está disponible. Incluir estas respuestas en las estadísticas generales de latencia distorsiona el análisis, ya que un error rápido no refleja un buen rendimiento.
Por el contrario, un error lento es aún más problemático, ya que combina el fallo con una mala experiencia de usuario. Por lo tanto, es imprescindible medir la latencia de los errores por separado, en lugar de limitarse a excluirlos de los cálculos.
Tráfico: volumen de solicitudes o carga del servicio
El tráfico representa la presión ejercida sobre un servicio y se mide mediante un indicador adaptado al tipo de sistema:
- Para una aplicación web, se suele utilizar el número de solicitudes HTTP por segundo.
- En un servicio de streaming de audio, las métricas pertinentes pueden ser el caudal de red o el número de sesiones simultáneas.
- En el caso de una base de datos SQL, se supervisará más bien el número de transacciones SQL por segundo.
El objetivo es elegir una métrica que refleje fielmente la carga real.
Errores: tasa de fallos o respuestas incorrectas
Los errores corresponden al volumen de solicitudes que no se ajustan al comportamiento esperado, visibles para el usario final. Pueden ser:
- Explícitos, como los códigos HTTP 5xx.
- Implícitos, por ejemplo, un código HTTP 200 que devuelve un contenido incorrecto.
- Definidos por una regla de negocio; por ejemplo, considerar como un fallo cualquier respuesta que supere un plazo contractual.
Cuando los códigos de protocolo no bastan para describir todas las situaciones de fallo, puede ser necesario añadir mecanismos internos para detectar degradaciones parciales.
El método de detección varía según el tipo de error: un equilibrador de carga puede detectar fácilmente los errores HTTP 500, pero solo una prueba de extremo a extremo puede identificar un contenido erróneo.
Saturación: proximidad a un cuello de botella
La saturación indica hasta qué punto un servicio se acerca a sus límites y pone de relieve los recursos más limitados. Puede manifestarse en forma de grupos de subprocesos saturados, atrasos en las solicitudes, una cola HTTP llena, etc.
En arquitecturas complejas, la saturación puede complementarse con una medición de la capacidad:
- ¿Puede el servicio absorber el doble de tráfico?
- ¿Solo puede soportar un 10 % de carga adicional?
- ¿Ya tiene dificultades con la carga actual?
Para servicios muy sencillos, puede bastar con el resultado de una prueba de carga. Pero en la mayoría de los casos, nos basamos en señales indirectas, como la utilización de la CPU o el rendimiento de la red, cuyos límites son conocidos. Un aumento de la latencia, especialmente del P99, suele ser un indicador temprano de saturación.
La saturación también incluye la capacidad de anticipar problemas, por ejemplo: "El volumen actual de datos indica que el disco de la base de datos se llenará en cuatro horas".
🟦 USE: ideal para diagnosticar la infraestructura
El marco USE (Utilization, Saturation, Errors), propuesto por Brendan Gregg, se utiliza para analizar los recursos del sistema. Se aplica a todos los recursos de hardware para diagnosticar problemas de infraestructura.
Utilización: porcentaje de uso de un recurso
La utilización mide la proporción de tiempo durante la cual un recurso está ocupado:
- Utilización de la CPU
- Rendimiento de E/S en lectura/escritura
- Memoria utilizada frente a memoria asignada
- Utilización de la interfaz de red
Sin embargo, hay que tener cuidado:
- Una utilización de la CPU del 100 % no siempre es un problema (por ejemplo, cargas de trabajo por lotes).
- Una utilización baja puede ocultar una saturación (por ejemplo, CPU en espera de E/S).
Saturación: los límites de un recurso
La saturación representa el límite físico de un recurso y es la causa de los cuellos de botella. A menudo es más crítica que la utilización. La saturación de las "Golden Signals" es una saturación funcional, relacionada con la capacidad del servicio para absorber la carga, mientras que la saturación USE es una saturación física, relacionada con el hardware o el kernel, que indica que un recurso ya no puede satisfacer la demanda.
Ejemplos:
- Saturación de la CPU con cola de ejecución de la CPU > número de núcleos
- Saturación del disco con cola del disco > 1
- Saturación de la red con retransmisiones TCP
Errores: fallos de hardware o anomalías
Se trata de errores de hardware o del sistema:
- Errores de disco (SMART)
- Errores de red (paquetes perdidos)
- Kernel panics
- OOM kills
🔴 RED: modelo para microservicios y API
El marco RED (Rate, Errors, Duration), popularizado por Prometheus, es una versión especializada de las Golden Signals, adaptada a las API HTTP/gRPC y a los microservicios. Se centra exclusivamente en las interacciones entre clientes y servicios, lo que lo convierte en una herramienta especialmente eficaz para diagnosticar problemas de rendimiento en arquitecturas distribuidas.
RED se utiliza a menudo en entornos de Kubernetes, Service Mesh (Istio, Linkerd), API Gateway o en aplicaciones sin servidor.
Rate: número de solicitudes por segundo
El Rate corresponde al número de solicitudes procesadas por un servicio en un periodo determinado. Es el indicador principal para comprender la carga real a la que está sometido un microservicio.
Debe observarse en RPS (Requests Per Second) o QPS (Queries Per Second) y puede segmentarse por punto final, método HTTP, tenant/cliente o por tipo de carga de trabajo.
Se trata de una medida crítica, ya que un cambio brusco en la tasa puede revelar:
- Un pico de tráfico inesperado.
- Un problema de escalado automático.
- Un efecto dominó debido a la caída de un servicio upstream.
- Un bucle de reintentos excesivo (a menudo invisible sin RED).
Errores: proporción de solicitudes fallidas
Las errores miden la proporción de solicitudes que fallan, ya sean errores explícitos o implícitos generados por un microservicio específico.
Hay varios tipos de errores que hay que distinguir:
- Errores de protocolo, como los códigos HTTP 4xx o 5xx.
- Errores de red, como los tiempos de espera agotados o los reinicios TCP.
- Errores de aplicación, como excepciones, validaciones o respuestas incoherentes.
- Errores de dependencias, como los relacionados con bases de datos, caché o servicios upstream.
Una tasa de error estable pero baja puede ocultar un problema de coherencia de los datos, un error en un punto final que se utiliza raramente o un deterioro progresivo de un servicio de terceros.
Duración: tiempo de procesamiento de las solicitudes
La duración corresponde al tiempo necesario para ejecutar una solicitud. A menudo se mide en percentiles (P50, P95, P99) mediante histogramas. A diferencia de la latencia de las "Golden Signals", se trata del tiempo de ejecución de un punto final específico, medido dentro del propio servicio.
La "Duración" suele ser la primera señal de un problema de rendimiento. Un aumento del P99 puede indicar una saturación de la CPU, un conflicto en una base de datos, un problema de recolección de basura, una latencia de red o una sobrecarga de un servicio upstream.
📊 Cómo unifica ServicePilot estos marcos
🔸 Golden Signals
Detecta los síntomas visibles: latencia, errores, saturación.
→ Ideal para las alertas y la visión global.
🔸 USE
Identifica las causas subyacentes: CPU saturada, disco lento, red congestionada.
→ Perfecto para diagnosticar nodos, máquinas virtuales y servidores.
🔸 RED
Analiza el comportamiento interno de los microservicios: puntos finales lentos, errores específicos.
→ Imprescindible para las arquitecturas "API-first".
ServicePilot ofrece una visión completa al permitir centralizar, correlacionar y visualizar estos tres enfoques en una única plataforma:
- Recopilación automática de métricas del sistema, de la red y de las aplicaciones.
- Cuadros de mando predefinidos para Kubernetes, servidores, bases de datos y API.
- Alertas basadas en Golden Signals, USE o RED.
- Correlación inteligente entre registros, métricas y trazas.
- Detección de anomalías mediante IA.
Conclusión: el poder de una observabilidad estructurada
Los equipos de DevOps y SRE ya no pueden conformarse con métricas aisladas. Los marcos Golden Signals, USE y RED aportan una estructura clara para comprender el estado de los sistemas y aplicaciones modernos.
Con ServicePilot, estos marcos de DevOps/SRE se vuelven operativos, correlacionados y aplicables, lo que permite:
- Priorizar lo que realmente importa.
- Estandarizar los cuadros de mando.
- Acelerar el diagnóstico.
- Alinear a los equipos en torno a un lenguaje común.
- Reducir el MTTR gracias a una mayor visibilidad.
