Revue de logs critiques pour l'analyse des incidents de Sécurité
Bien que cette checklist de contrôle des logs puisse être utilisée pour l'examen routinier des logs, ce processus d'examen des journaux critiques est une méthodologie d’analyse en cas de réponse à un incident de sécurité basée sur les travaux de chercheurs en sécurité informatique, Dr Anton Chuvakin et Lenny Zeltser.
L'avantage d'utiliser ServicePilot en s'inspirant et en appliquant cette méthodologie de sécurité opérationnelle réside dans le fait que ces tâches peuvent être effectuées et automatisées dans un seul outil. Ainsi, ces analyses automatiques peuvent être facilement insérées dans les processus de contrôle de routine afin de tirer profit de l'automatisation de l'examen des journaux et d'être plus proactif dans les réponses aux incidents de sécurité.
Approche méthodologique générale pour l'analyse des logs critiques
Voici les 8 étapes préconisées par ces chercheurs ainsi que 2 dernières optionnelles que nous pourrions ajouter:
-
Identifier les sources de journaux et les outils à utiliser pendant l'analyse
-
« Copier » les logs à un seul endroit pour les examiner
-
Minimiser le « bruit » en retirant les entrées répétitives et routinières du journal après avoir confirmé qu'elles sont bénignes
-
Déterminer si l’on peut se fier à l'horodatage des journaux ; en tenant compte des différences de fuseaux horaires
-
Veiller sur les changements récents, les pannes, les erreurs, les changements d'état, les événements d'accès et d'administration et autres événements inhabituels sur l’environnement
-
Revenir en arrière dans le temps à partir de maintenant pour reconstruire les actions après et avant l'incident
-
Corréler les activités entre les différents journaux pour obtenir une vue d'ensemble compréhensive et opérationnelle
-
Élaborer des théories sur ce qui s'est produit ; explorer les journaux pour les confirmer ou les réfuter
-
Automatiser l’analyse à grande échelle et de manière récurrente
-
Confirmer ou infirmer l’impact sur la production IT et les performances business
Analyse automatisée des logs et de la sécurité avec ServicePilot
1. Identifier les sources de journaux et les outils à utiliser pendant l'analyse
Une grande partie des renseignements opérationnels et de sécurité d'une organisation peut être tirée des fichiers de log générés par les serveurs, les équipements et les applications de l’entreprise.
Les sources potentielles de journaux de sécurité sont :
- Journaux du système d'exploitation du serveur et de la station de travail (Syslog, Windows Events, Sysinternals Sysmon...)
- Journaux d'application (serveur web, base de données....)
- Journaux d'outils de sécurité (Firewall, AV, IDS, IPS....)
- Logs de proxy et des applications
- Autres sources non-log pour les événements de sécurité (données de performance, métriques NetFlow, résultats des scripts, résultats des vérifications des fichiers YARA....).
ServicePilot permet non seulement de collecter les logs et évènements divers (Syslogs, Traps, logs W3C,...) mais offre aussi plusieurs interfaces permettant d'acccélerer le traitement des logs et les analyses : tableaux de bord, rapports PDF, alarmes, intégrations cartographiques, personnalisation des interfaces, bacs à évènements temps réel et historique, etc.
Chaque nouvelle source ou déploiement de collecteur comme la réception de Syslogs ou Windows Events de nouveaux équipements est automatiquement intégrée dans les tableaux de bord standards propres à chaque technologie. Les filtres, le calendrier et la création de tableaux de bord avec des widgets personnalisés permettent de segmenter facilement ce que l'on cherche pour repérer rapidement les anomalies dans la masse de maillons qui composent le périmètre de sécurité informatique d’une entreprise.
Le screenshot suivant montre un tableau de bord standard pour l'analyse des Windows Events avec top n par serveur, permettant le Drill-Down vers un Windows Event à investiguer en particulier.

2. "Copier" les logs à un seul endroit pour les examiner
Localisez vos sources de données et configurez ServicePilot via le fichier de configuration ou l'interface Web pour envoyer/recevoir les journaux et les données d'événements de sécurité. Il est difficile de jongler localement sur plusieurs machines ou faire du grep à tout va sur des environnements complexes et distribués pour comprendre ce qu'il se passe.
Voici les emplacements typiques des logs :
- Système d'exploitation Linux et applications centrales : /var/log
- Système d'exploitation Windows et applications centrales : Journaux des événements Windows (sécurité, système, application, répertoire Sysmon, répertoire spécifique, IIS...)
- Périphériques réseau : généralement enregistrés via Syslog ; certains utilisent des emplacements et des formats propriétaires
- Logs particulières, utiles et des formats propriétaires : ServicePilot utilise un parsing naturel de quelques champs pour les logs non formatés. Il est possible de créer des packages ou des analyses personnalisés afin de mieux comprendre ces messages.

Afin de simplifier l'analyse et la corrélation ultérieure, une bonne méthode consiste à créer une vue (sorte de conteneur ou de boîte regroupant des éléments disparates et/ou homogènes que l'on veut analyser) de type « Analyse-CVE-abc » ou « SecurityRoutine-xyz ».
Dans le cas où ces sources sont déjà collectées dans ServicePilot, nous pouvons simplement créer un raccourci de cette source ou Object Search (recherche automatisée dans les logs pouvant effectuer de nombreuses opérations type count, sum, etc.) pour éviter les problèmes de duplication.
3. Minimiser le « bruit » en retirant les entrées bénignes du journal
Il est indispensable de pouvoir minimiser le « bruit » en retirant les entrées répétitives et routinières du journal après avoir confirmé qu'elles sont bénignes.
Grâce à des filtres et des requêtes simples, nous pouvons filtrer et rétrécir la quantité d’événements pour minimiser progressivement le « bruit » et les événements bénins qui perturbent l’analyse. Des cases à cocher ou de simples filtres de requête peuvent faire l'affaire pour réduire la quantité de lecture (en particulier pour les événements Windows...).
Plusieurs étapes et techniques permettent de trouver l'aiguille dans la botte de logs, afin de comprendre facilement les dépendances et les impacts de l'incident, que ce soit dès le provisioning, par le biais d’analyses issues des tableaux de bord, par les bacs à évènements, ou grâce à des requêtes de type machine learning dans le moteur de recherche big data de ServicePilot (exemple : Le machine learning pour l'analyse des termes significatifs et d'anomalies dans les logs et évènements).


4. Déterminer si l’on peut se fier à l'horodatage des journaux
ServicePilot vous facilite la tâche et gère les horodatages ainsi que la gestion des fuseaux horaires en indexant toutes les données au format UTC et en affichant le bon fuseau horaire en fonction des paramètres utilisateur du navigateur Web ServicePilot. Pas de mal de tête, c'est fait pour vous !
5. Une veille sur les changements et les événements inhabituels sur l’environnement
Il faut veiller sur les changements récents, les pannes, les erreurs, les changements d'état, les événements d'accès et d'administration et autres événements inhabituels sur l’environnement.
- Ce qu'il faut rechercher sous Linux
Sous Linux, on peut chercher beaucoup de mots clés intéressants parmi les syslogs afin de détecter automatiquement :
- Les connexions réussies de l'utilisateur
- Les échecs de la connexion de l'utilisateur
- Les déconnexions de l'utilisateur
- Les modifications ou suppressions de compte d'utilisateur
- Les Actions Sudo ou les pannes de service
Des requêtes pré-fabriquées contenant ce type de recherche sont disponibles en standard, et permettent non seulement de faire de simples tops, mais aussi de voir ce même top avec un algorithme de machine learning afin de faire une analyse des termes significatifs pour les anomalies de surface (Top avec raking de proportion).
- Ce qu'il faut rechercher sur Windows
Sous Windows, les ID d'événements sont les principaux mécanismes d'écrémage rapide des évènements. La plupart des événements ci-dessous se trouvent dans le journal de sécurité ; beaucoup d'entre eux ne sont enregistrés que sur le contrôleur de domaine, et certains sont à activer car non enregistrés par défaut. On peut cependant facilement faire des tops sur :
- Les événements de connexion et de déconnexion de l'utilisateur (Successful logon, failed logon, logoff, etc.)
- Les changements de compte d'utilisateur
- Les changements de mot de passe
- Les services démarrés ou arrêtés, etc...
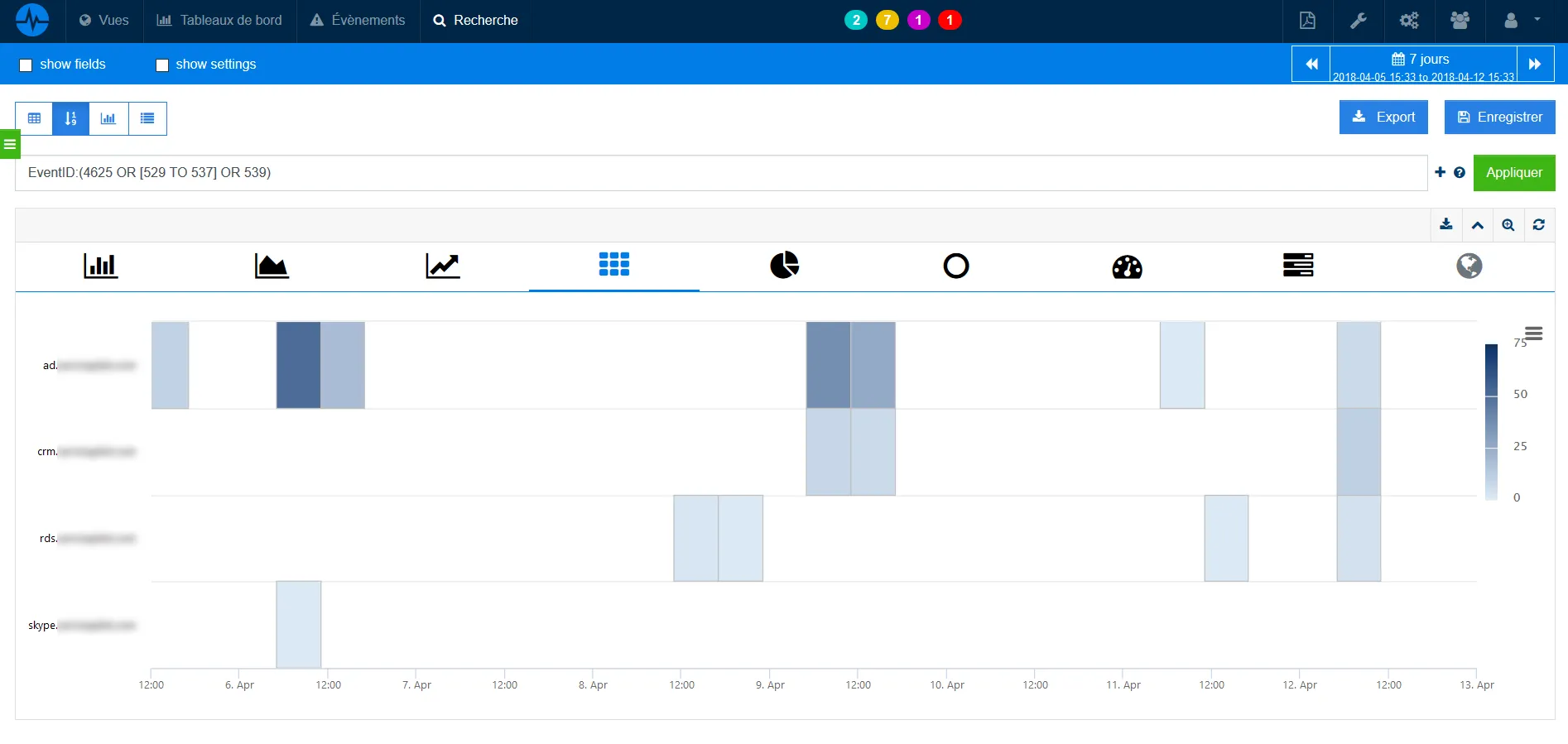
Le screenshot ci-dessous montre le suivi des connexions échouées sur plusieurs hôtes Windows sur le temps.

ServicePilot supporte aussi l'analyse des logs Windows Sysinternals Sysmon, qui permettent d'enregistrer des Windows Events détaillés sur les créations de processus, les connexions réseaux, les évènements du registre, les créations de fichiers et bien d'autres.
- Ce qu'il faut rechercher sur les périphériques réseau
Sur les périphériques réseau, il faut examiner les activités entrantes et sortantes. Les exemples ci-dessous montrent des extraits de journaux Cisco ASA (%ASA); d'autres appareils ont des fonctionnalités similaires.
- Trafic autorisé sur le pare-feu en recherchant les messages : “Built … connection”,“access-list … permitted”
- Trafic bloqué sur le pare-feu en recherchant les messages : “access-list … denied”,“deny inbound”,“Deny … by”
- Octets transférés (fichiers volumineux ?) en recherchant les messages: “Teardown TCP connection … duration … bytes …”
- Utilisation de la bande passante et des protocoles en recherchant les messages: “limit … exceeded”,“CPU utilization”
- Activité d'attaque détectée en recherchant les messages : “attack from”
- Changement de compte d'utilisateur en recherchant les messages : “user added”,“user deleted”,“User priv level changed”
- Accès administrateur en recherchant les messages : “AAA user …”,“User … locked out”,“login failed”
L'exemple ci-dessous nous montre un suivi des authentifications réussies vs échouées d'un VPN Cisco d'utilisateurs distants.

- Ce qu'il faut rechercher sur les serveurs Web
Sur les serveurs web, il faut faire attention à de nombreux paramètres et indicateurs afin de repérer facilement parmi des milliers ou millions de requêtes :
- Les tentatives excessives d'accès à des fichiers inexistants
- Les tentatives d'accès à du code (SQL, HTML) vu comme faisant partie de l'URL
- Les tentatives d'accès aux extensions que vous n'avez pas implémentées
- Les messages de Services Web arrêtés / démarrés / échoués
- Les accès aux pages "risquées" qui acceptent les entrées de l'utilisateur
- Les journaux de tous les serveurs du pool de load balancers
- Les codes d'erreur 200 sur des fichiers qui ne sont pas les vôtres
- Les échecs de l'authentification des utilisateurs
- Les codes HTTP 4xx et 5xx...

La puissance de ServicePilot pour l'analyse
L'objectif est d'utiliser les requêtes pré-intégrées incluses dans ServicePilot, de les personnaliser en fonction de votre environnement, de générer automatiquement des rapports PDF ou des tableaux de bord détaillés pour l'analyse en approfondie et la corrélation.
Par exemple, nous pourrions construire plusieurs rapports génériques pour chaque type de source de données et un global très haut niveau pour un examen rapide, ainsi que plusieurs tableaux de bord pour des accès rapides aux analyses détaillées.
Construire un tableau de bord global personnalisé surveillant trois sources différentes (par example syslogs, Windows events, et alertes Suricata sous format Syslog) et en faire ma page d'accueil est relativement simple avec les fonctions de glisser-déposer de l'interface web. La construction d'un rapport PDF est basée sur les mêmes principes.

Ayant centralisé mes sources et logs dans une vue « SecurityRoutine01 », je n'ai plus qu'à appliquer la vue filtre « SecurityRoutine01 » pour filtrer toute requête/tableau de bord ou rapport aux sources nécessaires.
Ayant déjà créé des widgets personnalisés ciblant les ressources que je veux, je n'ai pas besoin de filtrer les événements sur un hôte, une vue, une application ou une ressource. Je peux aussi créer de nouvelles requêtes afin d’étendre mon analyse au niveau applicatif (SharePoint, Exchange...) et middleware en surveillant par exemple les événements de sécurité clés dans Microsoft SQL Server :
- Changement d'autorité administrateur
- Changements d'autorisation
- Rôle des membres
- Modification des paramètres de sécurité
- Echec de connexion
- Exportation de données par des utilisateurs privilégiés
L'utilisation de l'architecture de ServicePilot et des fonctionnalités de Machine Learning natives permettent aussi d'améliorer l'analyse ou la réduction du « bruit » de supervision. ServicePilot dispose de requêtes pré-fabriquées afin d'aller plus vite pour obtenir et chercher ce qu'il faut dans chaque technologie pour faire, par exemple des analyses des termes significatifs et d'anomalies dans les logs et évènements.

6. Revenir en arrière dans le temps à partir de maintenant pour reconstruire les actions après et avant l'incident
Après avoir sauvegardé toutes les requêtes lors de l'étape précédente pour l'exportation automatique dans les tableaux de bord et les rapports, nous pouvons utiliser le calendrier dans les tableaux de bord ou générer des rapports PDF pour la période de temps sélectionnée.

7. Corréler les activités entre les différents journaux pour obtenir une vue d'ensemble compréhensive et opérationnelle
Dans le menu de création de tableau de bord, nous pouvons facilement diviser un tableau de bord en 3 parties, chacune représentant un type de journal, une métrique de performance, un aperçu de l'activité, une requête de sécurité, etc. en fonction de ses besoins.
La fonction de calendrier dans la visualisation du tableau de bord et le pointage graphique croisé de la souris permet de saisir facilement l'image complète et de corréler les événements entre les sources de logs IT et le « bruit » pour se concentrer sur l'analyse d'impact et les sources hétérogènes de logs ou de corrélation métrique.
Cela peut être réalisé à l’aide de tableaux de bord, de requêtes au travers du moteur de recherche ou grâce aux rapports PDF.
8. Élaborer des théories sur ce qui s'est produit ; explorer les journaux pour les confirmer ou les réfuter
Pour développer des théories sur ce qui s'est passé une fois que les journaux, les événements et les sources ont été confirmés et sélectionnés pour l'analyse post-légale, nous pouvons construire un modèle de rapport vierge pour décrire la théorie. Ce modèle peut être construit à partir de modèles bien connus de rapport de repos d'incident SANS ou de rapports d'incident Pentest. Ceux-ci permettent d'unifier et de normaliser le processus d'analyse des incidents de sécurité. Nous pouvons même essayer de créer une documentation d'incident de sécurité, pour simplifier la construction de la requête et enrichir mes rapports hebdomadaires automatisés avec une nouvelle surveillance automatique du renseignement de sécurité.

9. Automatiser l’analyse à grande échelle et de manière récurrente
Une fois l'incident de sécurité clos, nous pouvons automatiser l'analyse de cet incident avec une requête et l'inclure dans un rapport PDF hebdomadaire (par exemple chaque lundi à 8h un PDF Security Weekly Check est envoyé aux équipes). Cette tâche peut facilement être automatisée pour les contrôles de routine avec des rapports PDF programmés contenant le résultat de la liste précédente de requêtes possibles pour détecter les activités anormales dans l'ensemble de la pile informatique.

10. Confirmer ou infirmer l’impact sur les performances IT opérationnelles, l'approche SecOps pour la production
Il est aussi utile d’analyser les impacts des incidents de sécurité sur les performances opérationnelles de l’IT durant la période d’incident, chose facilement réalisable avec des tableaux de bord dédiés et les calendriers. Cela permet de facilement répondre à des questions du type : quel a été l’impact de l’évènement de sécurité abc sur le temps de réponse de mon application ? La copie d'écran suivante montre une vision DevSecOps pour surveiller une application en production.

