Les métriques DevOps et SRE : Golden Signals, USE et RED
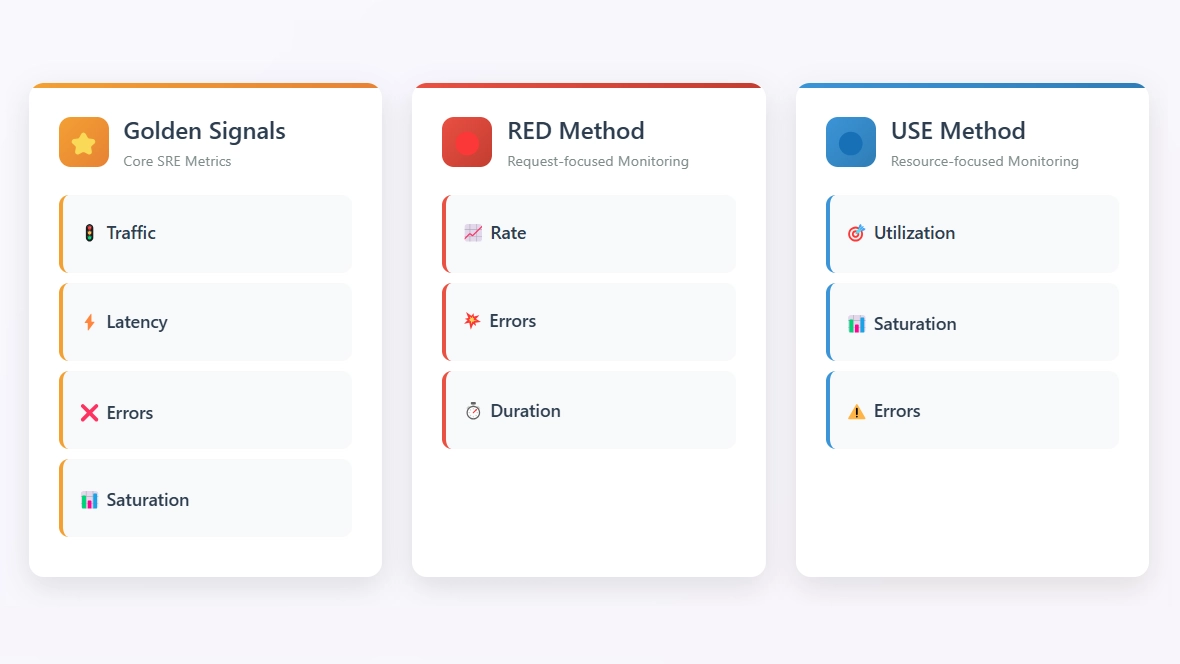
Les métriques essentielles DevOps & SRE : Golden Signals, USE et RED
L’observabilité moderne ne se limite plus à collecter des métriques : elle consiste à modéliser le comportement d’un système, à détecter les déviations et à corréler les signaux pour réduire drastiquement le MTTR. Les équipes DevOps et SRE doivent s’appuyer sur des métriques fiables, actionnables et standardisées pour garantir performance, disponibilité et expérience utilisateur.
C’est là que les frameworks Golden Signals, USE et RED entrent en jeu. Chacun apporte une grille de lecture complémentaire pour analyser la santé d’un système. Combinés à une plateforme d’observabilité comme ServicePilot, ils deviennent un levier puissant pour maîtriser la complexité.
⭐ Golden Signals : la base SRE pour superviser les services
Les Golden Signals sont conçus pour mesurer l’impact direct sur l’utilisateur final. Ils ont été popularisés par Google SRE et définissent 4 métriques essentielles pour tout service distribué (latence, trafic, erreurs, saturation).
Latence : temps de réponse perçu par l’utilisateur
La latence correspond au temps nécessaire pour traiter une requête du début à la fin. C'est le temps de réponse global du service, tel que perçu par l'utilisateur.
Il est essentiel de distinguer la latence des requêtes réussies de celle des requêtes échouées. Une erreur HTTP 500 peut parfois être renvoyée très rapidement, par exemple lorsqu’un service backend critique est indisponible. Inclure ces réponses dans les statistiques globales de latence fausse l’analyse, car une erreur rapide ne reflète pas une bonne performance.
À l’inverse, une erreur lente est encore plus problématique, car elle combine échec et mauvaise expérience utilisateur. Il est donc indispensable de mesurer la latence des erreurs séparément plutôt que de simplement les exclure des calculs.
Trafic : volume de requêtes ou charge du service
Le trafic représente la pression exercée sur un service et se mesure via un indicateur adapté au type de système :
- Pour une application web, on utilise généralement le nombre de requêtes HTTP par seconde.
- Dans un service de streaming audio, les métriques pertinentes peuvent être le débit réseau ou le nombre de sessions simultanées.
- Pour une base de données SQL, on surveillera plutôt le nombre de transactions SQL par seconde.
L’objectif est de choisir une métrique qui reflète fidèlement la charge réelle.
Erreurs : taux d’échecs ou réponses incorrectes
Les erreurs correspondent au volume de requêtes qui ne respectent pas le comportement attendu, visibles par l'utilisateur final. Elles peuvent être :
- Explicites, comme les codes HTTP 5xx.
- Implicites, par exemple un HTTP 200 renvoyant un contenu incorrect.
- Définies par une règle métier, par exemple, considérer toute réponse dépassant un délai contractuel comme un échec.
Lorsque les codes de protocole ne suffisent pas à décrire toutes les situations d’échec, il peut être nécessaire d’ajouter des mécanismes internes pour détecter les dégradations partielles.
La méthode de détection varie selon le type d’erreur : un load balancer peut facilement repérer les erreurs HTTP 500, mais seul un test bout‑en‑bout peut identifier un contenu erroné.
Saturation : proximité d’un goulot d’étranglement
La saturation indique à quel point un service approche de ses limites et met en avant les ressources les plus contraintes. Ils peuvent se manifester sous la forme de pool de threads saturés, des backlogs de requêtes, une queue HTTP pleine, etc.
Dans les architectures complexes, la saturation peut être complétée par une mesure de capacité :
- Le service peut‑il absorber deux fois plus de trafic ?
- Peut‑il seulement supporter 10 % de charge supplémentaire ?
- Est‑il déjà en difficulté avec la charge actuelle ?
Pour des services très simples, un résultat issu d’un test de charge peut suffire. Mais dans la majorité des cas, on s’appuie sur des signaux indirects comme l’utilisation CPU ou le débit réseau, dont les limites sont connues. Une augmentation de la latence, notamment du P99, est souvent un indicateur précoce de saturation.
La saturation inclut également la capacité à anticiper les problèmes, par exemple : "Le volume de données actuel indique que le disque de la base sera plein dans quatre heures."
🟦 USE : idéal pour diagnostiquer l’infrastructure
Le framework USE (Utilization, Saturation, Errors), proposé par Brendan Gregg, est utilisé pour analyser les ressources système. Il s’applique à toutes les ressources matérielles pour diagnostiquer les problèmes d’infrastructure.
Utilization : pourcentage d’utilisation d’une ressource
L'Utilisation mesure la proportion de temps pendant laquelle une ressource est occupée :
- Utilisation de CPU
- Débit d'I/O en lecture/écriture
- Mémoire utilisée vs mémoire allouée
- Utilisation de l'interface réseau
Cependant il faut faire attention :
- Une utilisation CPU à 100 % n’est pas toujours un problème (ex : workloads batch).
- Une utilisation faible peut masquer une saturation (ex : CPU en attente d’I/O).
Saturation : les limites d'une ressource
La saturation représente la limite matérielle d'une ressource et la source des goulots d'étranglement. Elle est souvent plus critique que l’utilisation. La saturation des Golden Signals est une saturation fonctionnelle, liée à la capacité du service à absorber la charge, tandis que la saturation USE est une saturation matérielle, liée au hardware ou au kernel, mettant en avant qu'une ressource ne suit plus la demande.
Exemples :
- Sauration de CPU avec Run queue CPU > nombre de cores
- Saturation disque avec file d'attente du disque > 1
- Saturation réseau avec retransmissions TCP
Errors : défauts matériels ou anomalies
Ce sont les erreurs matérielles ou système :
- Erreurs disque (SMART)
- Erreurs réseau (paquets perdus)
- Kernel panics
- OOM kills
🔴 RED : modèle pour microservices et API
Le framework RED (Rate, Errors, Duration), popularisé par Prometheus, est une version spécialisée des Golden Signals, adaptée aux API HTTP/gRPC et aux microservices. Il se concentre exclusivement sur les interactions entre clients et services, ce qui en fait un outil particulièrement efficace pour diagnostiquer les problèmes de performance dans des architectures distribuées.
RED est souvent utilisé dans les environnements Kubernetes, Service Mesh (Istio, Linkerd), API Gateway ou dans les applications serverless.
Rate : nombre de requêtes par seconde
Le Rate correspond au nombre de requêtes traitées par un service sur une période donnée. C’est l’indicateur principal pour comprendre la charge réelle appliquée à un microservice.
Il doit être observé en RPS (Requests Per Second) ou QPS (Queries Per Second) et peut être segmenté par endpoint, méthode HTTP, tenant / client ou par type de workload.
C'est une mesure critique car un changement brutal du Rate peut révéler :
- Un pic de trafic inattendu.
- Un problème de scaling automatique.
- Un effet domino dû à un service upstream en panne.
- Une boucle de retry excessive (souvent invisible sans RED).
Errors : proportion de requêtes échouées
Les Errors mesurent la proportion de requêtes qui échouent, qu’il s’agisse d’erreurs explicites ou implicites générées par un microservice spécifique.
Il existe plusieurs types d’erreurs à distinguer :
- Erreurs protocolaires comme les HTTP 4xx ou les 5xx.
- Erreurs réseau comme les timeouts ou les TCP resets.
- Erreurs applicatives comme les exceptions, les validations ou les réponses incohérentes.
- Erreurs de dépendances comme celles des bases de données, du cache ou des services upstream.
Un taux d’erreur stable mais faible peut masquer un problème de cohérence des données, un bug dans un endpoint rarement utilisé ou une dégradation progressive d’un service tiers.
Duration : temps de traitement des requêtes
La Duration correspond au temps nécessaire pour exécuter une requête. Elle est souvent mesurée en percentiles (P50, P95, P99) via des histogrammes. Contrairement à la latence des Golden Signals, c'est le temps d'exécution d'un endpoint spécifique, mesuré à l'intérieur du service.
La Duration est souvent le premier signal d’un problème de performance. Une augmentation du P99 peut indiquer une saturation CPU, une contention sur une base de données, un problème de Garbage collection, une latence réseau ou une surcharge d’un service upstream.
📊 Comment ServicePilot unifie ces frameworks
🔸 Golden Signals
Détecte les symptômes visibles : latence, erreurs, saturation.
→ Idéal pour l’alerting et la vision globale.
🔸 USE
Identifie les causes profondes : CPU saturé, disque lent, réseau congestionné.
→ Parfait pour diagnostiquer les nœuds, VM, serveurs.
🔸 RED
Analyse les comportements internes des microservices : endpoints lents, erreurs spécifiques.
→ Indispensable pour les architectures API-first.
ServicePilot offre une vision complète en permettant de centraliser, corréler et visualiser ces trois approches dans une plateforme unique :
- Collecte automatique des métriques système, réseau, applicatives.
- Tableaux de bord préconstruits pour Kubernetes, serveurs, bases de données, API.
- Alerting basé sur les Golden Signals, USE ou RED.
- Corrélation intelligente entre logs, métriques et traces.
- Détection d’anomalies grâce à l’IA.
Conclusion : la puissance d’une observabilité structurée
Les équipes DevOps et SRE ne peuvent plus se contenter de métriques isolées. Les frameworks Golden Signals, USE et RED apportent une structure claire pour comprendre la santé des systèmes et des applications modernes.
Avec ServicePilot, ces frameworks DevOps/SRE deviennent opérationnels, corrélés et actionnables, permettant de :
- Prioriser ce qui compte vraiment.
- Standardiser les tableaux de bord.
- Accélérer le diagnostic.
- Aligner les équipes sur un langage commun.
- Réduire le MTTR grâce à une meilleure visibilité.
