Observabilité des applications
Les piliers de l’observabilité
L’observabilité est essentielle pour garantir la fiabilité, les performances et la résilience des applications et infrastructures. Elle permet aux équipes de diagnostiquer et de résoudre les problèmes applicatifs de manière proactive, en collectant et en analysant des données provenant de diverses sources, telles que les métriques, les traces et les logs.
Dans le contexte du développement d’applications modernes, l’observabilité fait référence à la collecte et à l’analyse de ces données pour fournir des informations détaillées sur le comportement des applications. Elle est essentielle aux architectures dynamiques et aux environnements informatiques multi-Cloud d’aujourd’hui, permettant aux équipes d’ingénierie logicielle, informatiques, DevOps et SRE de collaborer pour prendre des décisions rapides basées sur des données télémétriques.
ServicePilot peut s’appuyer sur 5 principaux types de monitoring pour offrir une observabilité complète des applications :
Le tracing distribué suit les transactions et les appels entre microservices ou composants d’une application, en mesurant précisément la latence et les dépendances. Cela permet d’identifier les goulots d’étranglement ou les services défaillants.
L’observation des flux réseau sur les serveurs ou les Hosts offre une visibilité sur le trafic inter-applicatif, les volumes échangés, les temps de réponse réseau, les erreurs de connectivité et les comportements suspects.
Le RUM collecte des données directement depuis les navigateurs ou applications mobiles des utilisateurs réels. Cela permet de comprendre leur expérience (temps de chargement, erreurs JS, lenteurs…) dans le contexte réel d’utilisation.
Ce type de supervision simule des parcours utilisateurs grâce à des scripts ou des robots. Il permet de tester en continu la disponibilité, la latence et le comportement fonctionnel des services, indépendamment du trafic réel.
L’analyse centralisée des logs (système, applicatif, sécurité…) permet de diagnostiquer les incidents, d’enrichir les alertes ou d’investiguer des comportements anormaux.
Chaque pilier couvre une facette spécifique de l’environnement numérique. En les combinant, ServicePilot permet :
- Une corrélation intelligente des données
- Une détection proactive des anomalies
- Une analyse RCA (Root Cause Analysis) rapide et pertinente
- Une observabilité orientée expérience utilisateur
Traces distribuées
Qu’est ce que le tracing des applications ?
Dans des architectures dynamiques basées sur des microservices et des composants distribués, comprendre le chemin complet d’une requête utilisateur à travers l’application peut être un défi majeur. Les traces applicatives permettent de suivre chaque requête, du frontend jusqu’au backend, en enregistrant son parcours à travers l’ensemble des services, API, bases de données et Hosts impliqués. Il fournit une cartographie détaillée et chronologique des échanges entre les composants.
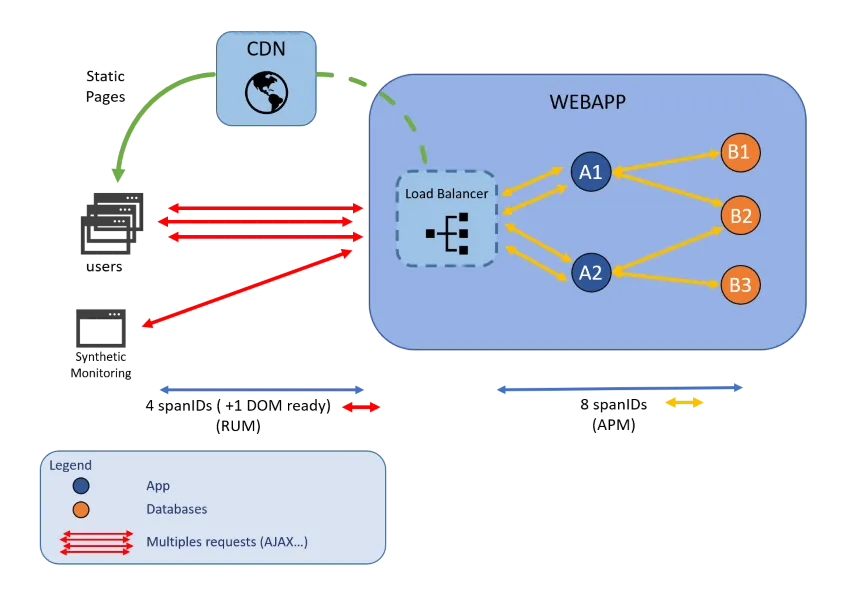
Dans un environnement composé de dizaines voire centaines de microservices, chaque action utilisateur (comme le chargement d’une page ou la validation d’un formulaire) peut déclencher des appels en cascade entre services. Des pages statiques peuvent être servies par CDN, des requêtes peuvent dépendre de sous-requêtes dans des bases de données…
Grâce aux technologies AppTrace, on peut facilement superviser :
- Les relations client/serveur (qui appelle qui)
- Combien de temps prend chaque étape d’une requête
- Où se situent les lenteurs ou erreurs dans le parcours d’exécution
On peut visualiser la chaîne complète d’exécution d’une transaction complexe et rapidement isoler :
- Des services lents ou surchargés
- Des dépendances externes défaillantes
- Des timeouts ou des appels bloqués
Collecte des traces et des données APM
L’instrumentation des applications est une étape essentielle pour activer le traçage distribué (APM) et collecter des traces précises à partir de vos applications. Avec ServicePilot, ce processus peut être rapide, flexible et adaptable, même dans des environnements complexes.
- Configurez l’application pour qu’elle envoie des traces, des métriques et des logs à un Agent ServicePilot à l’aide du protocole OTPL (OpenTelemetry Protocol) via http/protobuf, de Datadog ou des API Zipkin/HTTP. Consultez les détails par langage et framework ci-dessous.
- Configurez l’Agent ServicePilot pour qu’il écoute les traces d’application en définissant une Règle de provisioning automatique sous CONFIGURATION > Paramètres > Provisioning-auto. Ajoutez ou modifiez une règle de provisioning automatique en activant le Port AppTrace et en spécifiant les ports d’écoute corrects.
- Enfin, créez une Règle APM à partir des Paramètres pour affiner les définitions d’application et les détails d’instrumentation.
Si une application est déjà instrumentée à l’aide d’une norme de traçage open source telle que OpenTelemetry, Datadog ou Zipkin, ServicePilot peut s’intégrer de manière native pour collecter les traces APM à partir de l’instrumentation existante.
Si l’application n’est pas encore instrumentée :
- Les administrateurs peuvent instrumenter automatiquement leurs applications à l’aide d’une configuration OpenTelemetry Zero-code ou en utilisant les bibliothèques d’instrumentation automatique des applications du SDK DataDog.
- Les développeurs peuvent utiliser l’API et le SDK OpenTelemetry pour instrumenter leurs applications afin d’envoyer des métriques, des traces et des logs à un Agent ServicePilot. Les données peuvent être envoyées directement à un agent ServicePilot ou agrégées à l’aide d’un collecteur OpenTelemetry, puis exportées vers un Agent ServicePilot.
Modes d’instrumentation et langages
| Language | Documentation |
|---|---|
| .NET | Instrumentation .NET zero-code |
| Go | Instrumentation Go zero-code |
| Java | Instrumentation Java zero-code |
| JavaScript | Instrumentation JavaScript zero-code |
| PHP | Instrumentation PHP zero-code |
| Python | Instrumentation Python zero-code |
Outre d’autres paramètres de configuration, les paramètres suivants sont nécessaires pour l’intégration avec ServicePilot :
OTEL_DOTNET_AUTO_INSTRUMENTATION_ENABLED="true"
OTEL_DOTNET_AUTO_TRACES_INSTRUMENTATION_ENABLED="true"
OTEL_DOTNET_AUTO_METRICS_INSTRUMENTATION_ENABLED="true"
OTEL_DOTNET_AUTO_LOGS_INSTRUMENTATION_ENABLED="false"
OTEL_TRACES_EXPORTER="otlp"
OTEL_METRICS_EXPORTER="otlp"
OTEL_METRIC_EXPORT_INTERVAL="60000"
OTEL_LOGS_EXPORTER="none"
OTEL_EXPORTER_OTLP_ENDPOINT="http://<ServicePilot Agent host IP address>:4318"
OTEL_INSTRUMENTATION_HTTP_SERVER_CAPTURE_REQUEST_HEADERS="Content-Length,Transfer-Encoding,Range,Request-Range,Connection,Host,Accept,x-up-devcap-post-charset,Cache-Control,Referer,X-Filename"
OTEL_EXPORTER_OTLP_PROTOCOL="http/protobuf"
OTEL_EXPORTER_OTLP_TIMEOUT="10000"
| Language | Documentation |
|---|---|
| Java | Tracing des applications Java |
| Python | Tracing des applications Python |
| Ruby | Tracing des applications Ruby |
| Node.js | Tracing des applications Node.js |
| .NET Core | Tracing des applications .NET Core |
| .NET Framework | Tracing des applications .NET Framework |
| PHP | Tracing des applications PHP |
Les paramètres suivants sont nécessaires pour l’intégration avec ServicePilot :
DD_AGENT_HOST="<ServicePilot Agent host IP address>"
DD_TRACE_CLIENT_IP_ENABLED="true"
DD_RUNTIME_METRICS_ENABLED="true"
DD_PROFILING_ENABLED="false"
DD_TRACE_HEADER_TAGS="Content-Length,Transfer-Encoding,Range,Request-Range,Connection,Host,Accept,x-up-devcap-post-charset,Cache-Control,Referer,X-Filename"
Les traceurs et l’instrumentation Zipkin documentent les bibliothèques prenant en charge l’instrumentation du code d’application afin d’envoyer des traces à un Agent ServicePilot.
| Language | Documentation |
|---|---|
| C# | Zipkin4net |
| Go | Zipkin Library for Go |
| Java | Brave |
| JavaScript | Zipkin JS |
| Ruby | ZipkinTracer: Zipkin client for Ruby |
| Scala | zipkin-finagle |
Utilisez le protocole Zipkin/HTTP pour exporter des données vers un Agent ServicePilot sur le port TCP 9411
Les développeurs peuvent utiliser les bibliothèques d’instrumentation OpenTelemetry pour intégrer des traces, des métriques et des logs dans leur application.
| Language | Documentation |
|---|---|
| C++ | Instrumentation du code C++ |
| C#/.NET | Instrumentation du code .NET |
| Erlang/Elixir | Instrumentation du code Erlang/Elixir |
| Go | Instrumentation du code Go |
| Java | Instrumentation du code Java |
| JavaScript | Instrumentation du code JavaScript |
| PHP | Instrumentation du code PHP |
| Python | Instrumentation du code Python |
| Ruby | Instrumentation du code Ruby |
| Swift | Instrumentation du code Swift |
Des intégrations existantes pour les applications et les frameworks sont également disponibles.
- Bibliothèques d’instrumentation hébergées dans les archives OpenTelemetry.
- OpenTelemetry tient à jour une liste des intégrations d’instrumentation OpenTelemetry dans son registre.
Visualisation des données des traces APM
Les données collectées sont disponibles depuis plusieurs interfaces de ServicePilot, offrant à la fois des tableaux de bord globaux et des interfaces dédiées pour un diagnostic contextualisé.
Les tableaux de bord standards des traces APM sont disponibles avec des vues consolidées ou individuelles sous la section DASHBOARDS dans AppTrace > AppService ou AppHost ou AppSummary en fonction de la granularité de supervision souhaitée.
- Les données collectées peuvent être consultées globalement en sélectionnant la catégorie souhaitée.

- Les données peuvent également être consultées pour un élément spécifique d’une catégorie.
Davantage d’interfaces spécifiques permettent une exploration granulaire des requêtes sous la section DASHBOARDS dans AppTrace > Requêtes, AppTrace > Applications, AppTrace > L7 Map ou AppTrace > Profiler.
Lorsque la colonne Traceid contient une icône de loupe, on peut effectuer un drill-down vers la trace APM pour afficher les détails des transactions d’une requête.
La page AppTrace Requêtes donne l’analyse détaillée des transactions applicatives. Les données présentées offrent une analyse précise de la performance et du comportement applicatif, notamment avec le nombre de requêtes par minutes par transaction, la satisfaction utilisateur et d’autres métriques applicatives.
Grâce à la page AppTrace L7 Map, un affichage relationnel par section de vos différents systèmes se crée. Il est possible d’identifier les différents problèmes que pourraient rencontrer les applications supervisées. Vous pouvez par la suite et grâce à l’affichage de l’architecture trouver très rapidement quel serveur ou quel service est à l’origine de l’incident pour résoudre le problème dans les plus brefs délais.
Flux réseau
Que sont les flux réseau des Hosts ?
NetTrace est la technologie de ServicePilot qui permet de capturer et analyser en profondeur les échanges réseau entrants et sortants d’une machine (Windows / Linux / IBM z/OS). En supervisant les flux réseaux de plusieurs serveurs, vous pouvez observer les échanges entre des groupes de Hosts et entre les composants applicatifs des systèmes.
Grâce à la supervision des flux réseaux sur les serveurs et/ou les conteneurs, vous pouvez analyser :
- Qui parle à qui ?
- Sur quels ports et protocoles ?
- A quelle fréquence ?
- Avec quels volumes de données…
L’Agent ServicePilot capture les flux IP et produit des résumés de conversation réseau structurés en plus des interfaces détaillées temps réel. Les interfaces Web fournissent des visualisations claires et interactives des communications réseau au sein des infrastructures.
À quoi ça sert ?
NetTrace est un outil système de visibilité réseau orienté applicatif, qui permet notamment de :
- Cartographier les dépendances entre applications, services, serveurs ou microservices.
- Identifier les problèmes : latence, saturation, retransmissions TCP, erreurs, etc.
- Détecter des comportements anormaux ou suspects : échanges inattendus, ports non standards, flux vers l’extérieur, etc.
- Valider la conformité des flux réseau (par rapport aux règles de sécurité, segmentation, pare-feu ou zones de confiance).
- Uniformiser la supervision des flux des systèmes quel que soit le choix d’hébergement (Cloud, Hybride, On-Premise).
Collecte des données des flux réseau
Pour collecter les traces réseau, il suffit d’installer un Agent ServicePilot sur les machines (Hosts) à superviser. Ensuite, il faut créer une règle de Provisioning-auto en cochant l’option NetTrace depuis l’interface ServicePilot sous la section CONFIGURATION dans Paramètres > Provisioning-auto.
Visualisation des données NetTrace
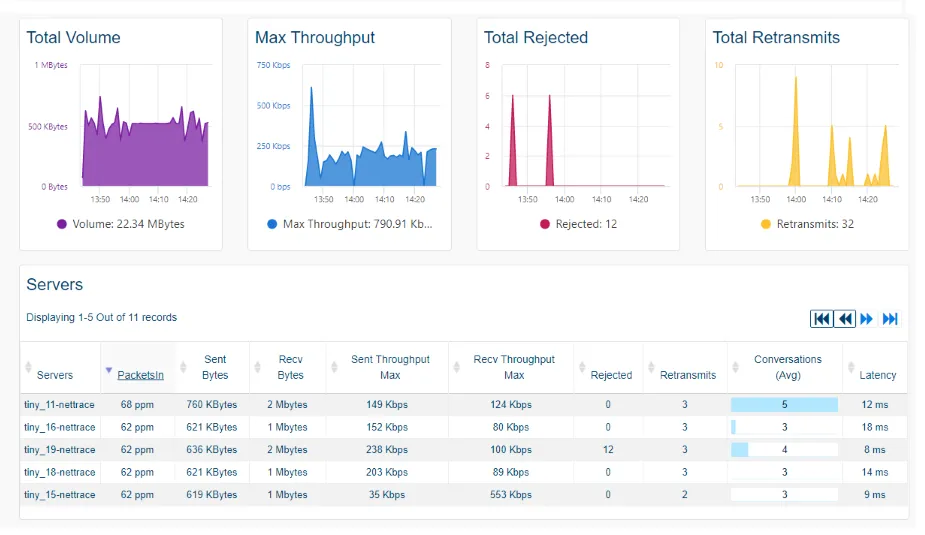
Les données collectées sont disponibles depuis plusieurs interfaces de ServicePilot, offrant à la fois des tableaux de bord globaux et des interfaces dédiées pour un diagnostic contextualisé.
Les tableaux de bord standards des flux des serveurs/applications sont disponibles avec des vues consolidées ou individuelles sous la section DASHBOARDS dans NetTrace > NetHost ou NetProcess en fonction de la granularité de supervision souhaitée.
Davantage d’interfaces permettent une exploration granulaire des conversations sous la section DASHBOARDS dans NetTrace > Conversations, NetTrace > L4 Map, NetTrace > Public ou NetTrace > PCAP.
La page NetTrace Conversations permet de visualiser les différentes connexions établies entre les serveurs et/ou les applications supervisés par les Agents ServicePilot. La colonne de filtres permet de cibler les recherches en filtrant par IP, port, protocole etc. pour observer les données précises du trafic réseau (conversations, connexions bloquées, rejetées, octets par secondes…).
Grâce à la page NetTrace L4 Map, un affichage relationnel par section de vos différents systèmes se crée. Il est possible d’identifier les différents problèmes que pourraient rencontrer les systèmes monitorés sur votre réseau. Vous pouvez par la suite et grâce à l’affichage de l’architecture trouver très rapidement quel serveur ou quel service est à l’origine de l’incident pour résoudre le problème dans les plus brefs délais.
La page NetTrace Public affiche les communications entrantes/sortantes depuis/vers des IP publiques.
La page NetTrace PCAP offre une visualisation précise et rapide de tout le trafic transitant en live dans un réseau. Après la sélection d’un réseau ou d’un Host, il est possible de visualiser les données et les différents liens associés de plusieurs manières, sous forme de tableau ou sous forme de graphes, pour obtenir une vue d’ensemble en temps réel sur l’état du réseau sélectionné. Cette page PCAP offre également une fonctionnalité très intéressante permettant à tout moment de capturer le trafic réseau sur une machine et en faire une trace PCAP selon divers filtres pouvant être renseignés (IP, ports, protocole…) téléchargeable automatiquement depuis le navigateur.
Real User Monitoring
Qu’est ce que le Real User Monitoring ?
Le Real User Monitoring (RUM) permet d’observer les performances et le comportement des utilisateurs réels de vos applications web, directement depuis leur navigateur. Contrairement au Synthetic Monitoring, qui repose sur des tests simulés, le RUM mesure l’expérience utilisateur telle qu’elle est réellement vécue, en tenant compte des conditions réseau, du type de terminal, de la géographie et de l’environnement du client.
Avec le RUM, ServicePilot collecte des données précieuses telles que :
- Le temps de chargement des pages
- Les erreurs JavaScript rencontrées
- Les performances réseau et applicatives
- La géolocalisation des utilisateurs
- Les types de navigateurs, OS et résolutions d’écran
Cela permet de comprendre, mesurer et améliorer la véritable expérience utilisateur en continu, à la fois d’un point de vue technique et ergonomique.
Qu’est ce que le Session Replay RUM ?
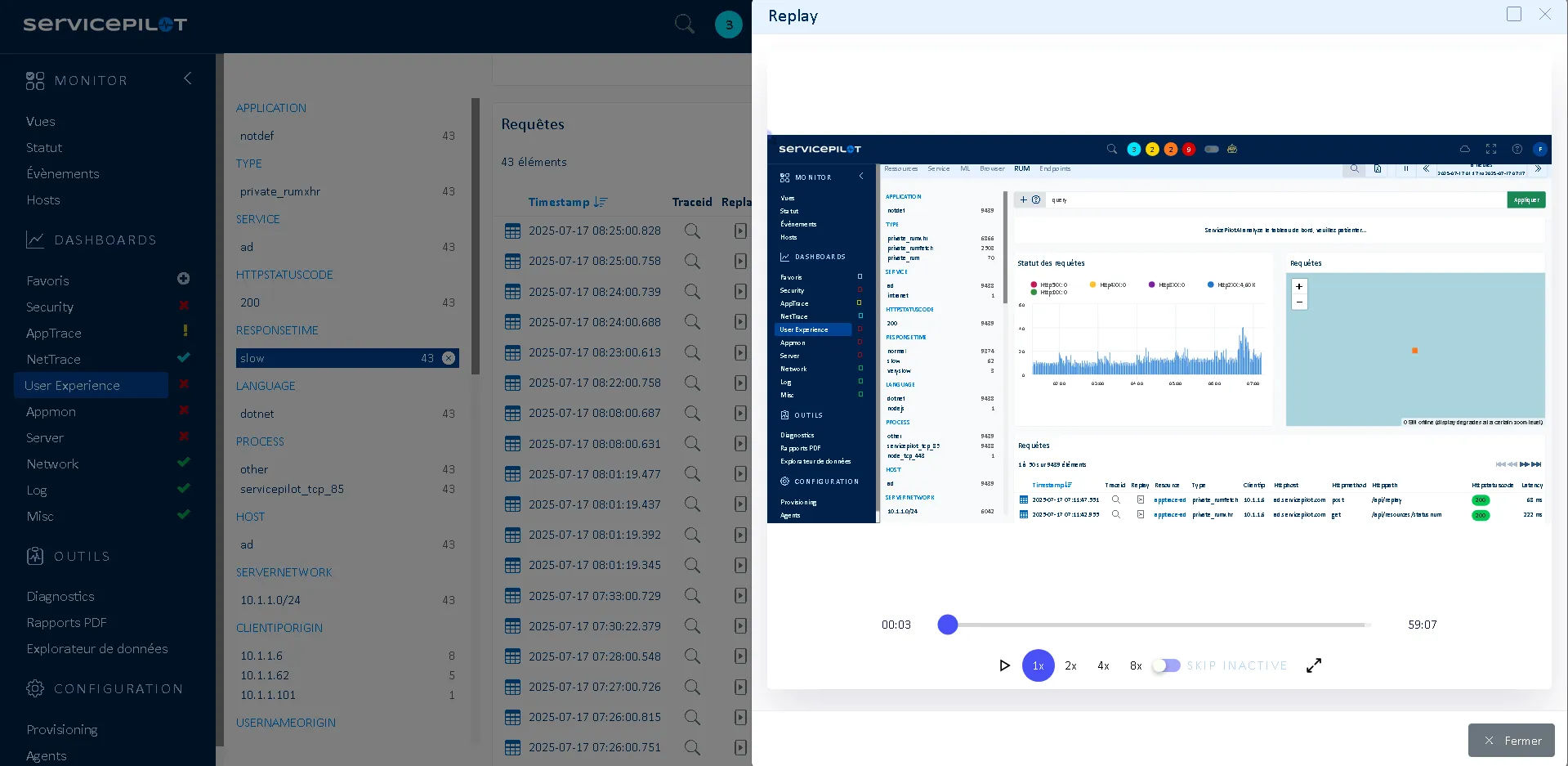
La fonctionnalité Session Replay permet d’enregistrer et de rejouer les interactions des utilisateurs avec votre application web comme les clics, les mouvements de souris, la navigation et les erreurs. Elle vient compléter le Real User Monitoring en apportant un lecteur visuel pour l’analyse comportementale de l’expérience utilisateur.
Cela permet de revisionner le ressenti et le parcours d’un utilisateur pour diagnostiquer efficacement les problèmes d’ergonomie, de performance ou des bugs fonctionnels.
Collecte des données RUM
Pour collecter les métriques Real User Monitoring (RUM) dans vos pages web, il est nécessaire d’intégrer le script RUM ServicePilot.
Selon votre environnement, plusieurs méthodes d’intégration sont possibles :
- Serveurs d’applications Java (Tomcat, Jetty). Utilisez un plugin ServicePilot dédié pour injecter automatiquement le script RUM dans les réponses HTML générées par vos applications. Aucune modification manuelle du code n’est nécessaire. Cela permet une intégration centralisée et transparente dans des environnements Java Web classiques basés sur JSP, servlets ou des frameworks comme Spring MVC.
- Serveurs Web / Proxys (Apache, NGINX, IIS…). Configurez vos serveurs ou proxys pour modifier les pages HTML servies, en injectant dynamiquement le script RUM. Cette méthode peut être privilégiée lorsque vous ne pouvez pas modifier le code applicatif mais que vous contrôlez la couche de livraison web. Par exemple, IIS permet d’utiliser l’extension URL Rewrite avec un module d’injection HTML.
- Pages Web statiques ou applications SPA. Ajoutez manuellement le script RUM dans le code source de vos pages web, idéalement dans la section <head> . Cela convient pour les sites HTML statiques, les Single Page Applications (React, Angular, Vue.js…) ou les intégrations CMS (WordPress, Drupal…). L’insertion manuelle dans le code permet aussi d’établir une instrumentation fine, page par page ou conditionnelle selon l’environnement.
Où récupérer le script RUM ?
Les instructions détaillées pour l’instrumentation RUM sont accessibles depuis l’interface ServicePilot sous la section CONFIGURATION dans Paramètres > Règles APM > Instrumentation RUM. Vous y trouverez le script prêt à l’emploi ainsi que les options de configuration adaptées à vos cas d’usage.
Activation du Session Replay
L’option du Session Replay est activable dans la configuration du script JavaScript RUM. Une fois que le script est mis à jour et déployé sur les pages ciblées, les sessions des utilisateurs de l’application supervisée seront collectées.
Visualisation des données RUM & Session Replay
Les données collectées sont disponibles depuis plusieurs interfaces de ServicePilot, offrant à la fois des tableaux de bord globaux et des interfaces dédiées pour un diagnostic contextualisé.
Les tableaux de bord standards du RUM ServicePilot avec des vues consolidées ou individuelles sont disponibles sous la section DASHBOARDS dans User Experience > Rum.
En allant dans Détails des requêtes du RUM, la colonne Replay affiche une icône lorsqu’un Session Replay est disponible.
Monitoring synthétique
Qu’est ce que le monitoring synthétique ?
Le monitoring synthétique est une technique de supervision qui simule une ou plusieurs actions utilisateurs sur un site Web, indépendamment du trafic réel. Tester des pages critiques ou des parcours utilisateurs à intervalles de temps réguliers permet de surveiller la disponibilité, la performance et le bon fonctionnement applicatif des services Web.
Collecte des données du monitoring synthétique
ServicePilot propose plusieurs packages pour mettre en place une supervision synthétique adaptée à vos besoins :
ServicePilot webcheck – vérification HTTP(S)
Le package user-webcheck permet de superviser les réponses d’un serveur à l’aide d’une requête HTTP(S) émise par un Agent ServicePilot :
- Collecte de code HTTP, temps de réponse, informations certificat SSL.
- Supporte les requêtes GET/POST, avec en-têtes personnalisés, code HTTP attendu…
- Permet d’extraire des données numériques de la page (ex. : nombre d’éléments, valeur d’un compteur).
Bien qu’élémentaire en apparence, ce package peut devenir un puissant levier de supervision lorsqu’il est déployé stratégiquement. En multipliant les points de test (via des Agents ServicePilot positionnés dans différentes zones géographiques, derrière des proxies ou sur des réseaux à latence variable), il est possible d’obtenir une vision assez réelle et distribuée de l’expérience utilisateur.
ServicePilot web-scenario – scénarios multi-étapes
Le package user-web-scenario offre la supervision des temps de réponse d’un serveur via une série de requêtes HTTP(S) émises par l’Agent ServicePilot. Chaque étape du scénario peut aussi être personnalisée selon les besoins.
Toutes les requêtes sont exécutées par l’Agent ServicePilot à un intervalle régulier, offrant une supervision continue des performances.
Intégration de tests fonctionnels externes
Pour compléter les packages natifs, ServicePilot propose différents packages standards pour intégrer les résultats de tests fonctionnels provenant d’outils tiers. Ces résultats peuvent être remontés dans ServicePilot sous forme de rapports horodatés, enrichissant les tableaux de bord avec les données des tests automatisés.
| Logiciels Tiers | Description | Packages ServicePilot |
|---|---|---|
| Lighthouse | Outil d’audit automatisé développé par Google pour évaluer la performance, l’accessibilité, le SEO et les bonnes pratiques des pages web. | Intégration Lighthouse |
| Puppeteer | Librairie Node.js permettant d’automatiser un navigateur Chrome ou Chromium via une API haut niveau même dans des SPAs et sur des contenus dynamiques. Cela permet d’émuler des scénarios complexes avec navigation, clics, saisies, délais, et captures d’écran. | Intégration Puppeteer |
| NightWatchJS | Framework E2E basé sur Node.js et Selenium. Idéal pour valider les flux critiques avec des assertions (présence de texte, statut HTTP, champs remplis, etc.). | Intégration NightWatchJS |
| Playwright | Solution multi-navigateurs permettant de tester sur Chrome, Firefox, Safari. Supporte les tests parallèles, les assertions visuelles et les interactions riches (drag & drop, uploads…). | Intégration Playwright |
| SikuliX | Utilise la reconnaissance visuelle pour automatiser des interactions basées sur l’interface graphique (UI). Très utile lorsque les éléments DOM sont inaccessibles ou dynamiques (idéal pour les applications legacy ou non HTML). | Intégration SikuliX |
Visualisation des données du monitoring synthétique
ServicePilot propose des tableaux de bord standards, avec des vues consolidées ou individuelles des données sous la section DASHBOARDS dans User Experience > Web-Scenario ou WebCheck.
Les données du Synthetic Monitoring provenant d’outils tiers sont centralisés dans des tableaux de bord dédiés sous la section DASHBOARDS dans Appmon > [nom du package].
Logs des applications
Les logs applicatives, systèmes et de sécurité sont une source importante pour diagnostiquer des incidents en profondeur ou enrichir des alertes avec du contexte. Dans une approche moderne d’observabilité, les logs viennent compléter les traces applicatives, les métriques et les tests synthétiques.
ServicePilot prend en charge l’ingestion des formats de logs courants, ce qui lui permet de collecter et de normaliser de manière transparente les données provenant d’applications et d’infrastructures diverses. Que les journaux soient générés au format W3C pour serveurs web IIS, sous forme de flux Syslog traditionnels, des Windows Events provenant d’environnements Microsoft ou selon d’autres normes courantes, ServicePilot les unifie au sein d’un pipeline d’analyse cohérent. Cette flexibilité permet aux équipes de surveiller, de corréler et d’analyser les événements dans des environnements hétérogènes.
Parmi tous les différents formats de journaux (W3C, Syslog, journaux d’événements Windows, CEF, LEEF, etc.), les principaux types de journaux peuvent se répartir en un ensemble de catégories fonctionnelles. Ces catégories décrivent ce que représentent les journaux, quel que soit leur format.
| Type de log | Description |
|---|---|
| Logs d’accès | Enregistrent qui a accédé à un service, quand, d’où et comment. Courants dans les journaux W3C, CLF, JSON et les journaux de proxy. |
| Logs d’événements | Capturent les événements du système ou des applications, tels que les démarrages de services, les modifications de configuration ou les avertissements. Typiques des journaux Syslog et des journaux d’événements Windows. |
| Logs d’erreurs | Signalent les échecs, les exceptions, les plantages et les comportements inattendus. Ils sont présents dans presque tous les formats. |
| Logs de sécurité | Authentification, autorisation, événements de pare-feu, tentatives d’intrusion. Souvent structurés aux formats CEF, LEEF, Syslog et dans les journaux de sécurité Windows. |
| Logs d’audit | Suivi des actions administratives, des modifications de configuration et des opérations liées à la conformité. Courants dans les journaux cloud, les journaux de base de données et les journaux d’événements Windows. |
| Logs de transactions | Représentent les opérations métier ou de base de données (paiements, écritures de données, validations). On les trouve dans les journaux JSON, les journaux de bases de données et les formats spécifiques aux applications. |
| Logs de performances | Métriques, latence, débit, utilisation des ressources. Souvent générés au format JSON ou Syslog structuré. |
| Logs de debug | Informations internes très détaillées destinées au dépannage. Courants au format JSON et dans des formats spécifiques aux applications. |
La centralisation des logs dans ServicePilot permet de :
- Rechercher rapidement dans les logs de vos systèmes ou vos applications.
- Corréler les logs avec les traces, alertes et événements réseau.
- Avoir un historique détaillé de chaque événement technique pour les audits, les diagnostics ou l’analyse de comportements anormaux.
Collecte des logs au format W3C
ServicePilot prend en charge l’ingestion des logs au format W3C, utilisés notamment par les serveurs web IIS ou par certains load balancers et proxies. Ces logs peuvent inclure des informations sur les requêtes HTTP, les statuts, les délais de traitement ou encore les adresses IP sources. Si le site est déjà instrumenté avec RUM, les logs W3C peuvent être enrichies avec des headers de requête personnalisés pour améliorer le suivi utilisateur.
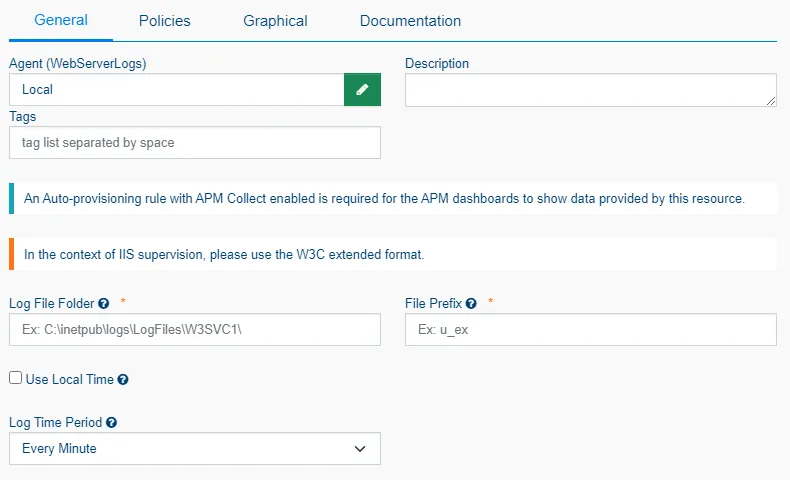
Le package apptrace-appservice-w3c permet de collecter automatiquement les logs W3C présentes sur le serveur, selon un chemin défini lors de la configuration.
Il permet notamment de :
- Visualiser les requêtes HTTP.
- Analyser les temps de réponse.
- Identifier les erreurs applicatives (codes 4xx/5xx).
Visualisation des données de logs W3C
Les tableaux de bord standards des Logs W3C sont disponibles avec des vues consolidées ou individuelles sous la section DASHBOARDS dans AppTrace > appservice-w3c.
Davantage d’interfaces permettent une exploration granulaire des requêtes sous la section DASHBOARDS dans AppTrace > Applications, AppTrace > Requêtes ou AppTrace > L7 Map.
