Matrice de flux automatique : 5 fonctions clés pour votre supervision
Observabilité : comprendre la matrice des flux réseau
Une matrice de flux est une représentation visuelle et structurée de l’ensemble des communications entre serveurs, applications, services et processus. Elle permet de visualiser, en un coup d’œil, qui parle à qui, sur quels ports, via quels protocoles et avec quelle intensité. Les tableaux et les cartographies dynamiques deviennent un outil central pour comprendre les dépendances applicatives, identifier les chemins critiques et analyser le comportement réel des systèmes en production.
Les cas d’usage sont nombreux:
- En segmentation réseau, la matrice de flux permet de valider les règles de filtrage, de détecter les communications inattendues et de préparer des projets Zero Trust.
- En sécurité, elle met en évidence les flux anormaux, les communications latérales suspectes ou les comportements déviants.
- Pour les équipes applicatives, elle révèle les dépendances réelles entre microservices, bases de données et composants tiers.
- Enfin, lors du troubleshooting, elle accélère l’identification de la source d’un ralentissement ou d’une défaillance en montrant immédiatement où un flux se bloque ou se dégrade.
Les matrices de flux traditionnelles, souvent basées sur des exports NetFlow, sFlow ou sur des sondes réseau, présentent des limites importantes. Elles dépendent de la visibilité offerte par l’infrastructure, ne capturent pas toujours les communications internes aux serveurs, et manquent de contexte applicatif. Dans des environnements virtualisés, conteneurisés ou multi‑cloud, ces approches peinent à suivre la réalité des échanges, car un même flux peut traverser plusieurs couches logiques avant d’être visible.
C’est pourquoi une matrice de flux construite directement depuis les serveurs et les processus offre une précision nettement supérieure. En observant le trafic à la source — au niveau du kernel, du processus et de l’application — elle permet de relier chaque communication à son origine réelle, d’identifier le service impliqué et de comprendre la finalité du flux. Cette approche élimine les zones d’ombre, garantit une visibilité complète même dans des architectures complexes et fournit une base fiable pour la supervision, la sécurité et l’optimisation des performances.
La technologie NetTrace de ServicePilot s’appuie précisément sur cette approche : observer le trafic directement au niveau du serveur et du processus pour produire une matrice de flux complète, contextualisée et immédiatement exploitable. Cette visibilité fine permet de comprendre les dépendances réelles, d’identifier les anomalies et d’obtenir une supervision réellement unifiée.
5 fonctionnalités clés pour l'analyse du trafic et la matrice de flux
Voici 5 fonctionnalités essentielles que toute solution d’observabilité devrait proposer pour offrir une vision fiable, détaillée et actionnable du trafic depuis vos systèmes.
1. Collecte de trafic multi-plateformes et indépendante du réseau
Une solution d’observabilité réellement opérationnelle doit collecter le trafic directement au niveau des interfaces système, sans dépendre d’un équipement intermédiaire. NetTrace permet cette approche en s’intégrant nativement sur Windows et Linux, qu’ils s’exécutent sur des serveurs physiques dédiés, des machines virtuelles, des infrastructures hypervisées, des conteneurs ou des orchestrateurs tels que Kubernetes.
Cette collecte locale offre plusieurs avantages techniques. Elle capture d’abord l’intégralité des flux réseaux — y compris ceux qui ne quittent jamais le nœud, comme les communications interprocessus encapsulées ou les flux internes à un cluster. Elle élimine aussi la perte d’information liée aux proxys réseau, aux overlays, aux tunnels SD-WAN ou aux mécanismes NAT qui rendent les flux difficiles à interpréter depuis l’extérieur. Enfin, elle garantit que l’analyse reste cohérente même lorsque le réseau est segmenté, chiffré, routé de manière dynamique ou supporte des mécanismes d’équilibrage avancés.
Cette indépendance vis-à-vis de l’infrastructure réseau constitue une condition essentielle pour obtenir une vision fiable dans des environnements modernes, même dans les architectures les plus segmentées ou distribuées.
En résumé, la collecte est unifiée, simple à déployer et immédiatement exploitable.
2. Matrice de flux automatique pour une supervision unifiée
Collecter des données est une chose mais les rendre lisibles, accessibles et exploitables en est une autre.
Les infrastructures modernes se caractérisent par une hétérogénéité croissante : multiplicité de serveurs, diversité des zones réseau, hybridation cloud/on-premise, mécanismes de résilience distribuée. Dans ce contexte, disposer d’une vision centralisée du trafic devient indispensable pour corréler les comportements entre plusieurs périmètres.
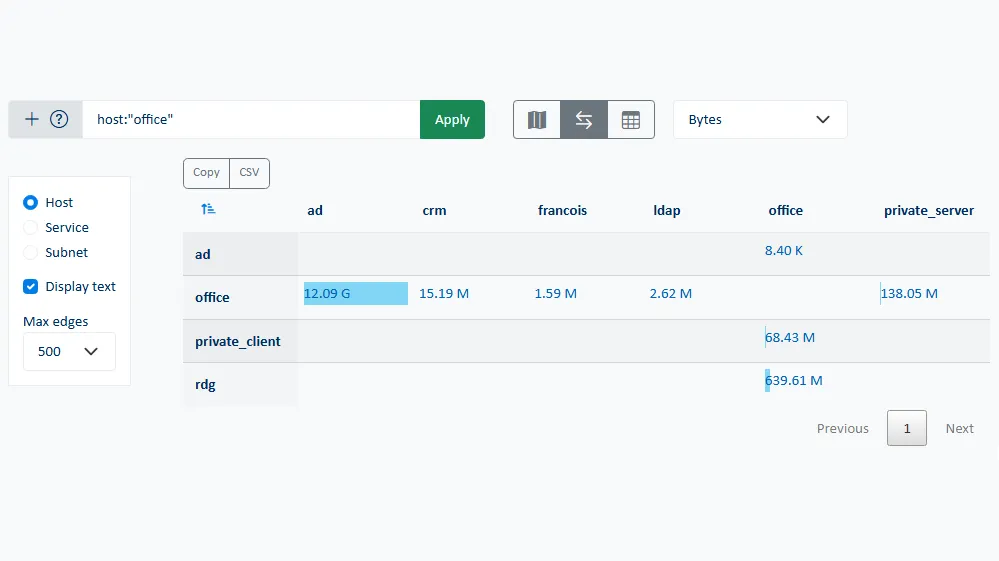
NetTrace consolide en temps réel les informations collectées sur l’ensemble des serveurs et les expose via une interface unifiée. Cette vue agrégée permet d’observer l’activité réseau globale mais aussi de naviguer de manière fluide du niveau macro (topologie fonctionnelle, flux dominants, volumes) au niveau micro (processus individuel, socket spécifique, interrogation d’un service). Les matrices de flux dynamiques permettent de suivre les variations de charge en temps réel, d’identifier les serveurs les plus sollicités ou de suivre l’évolution d’un flux particulier tout au long de sa durée de vie.
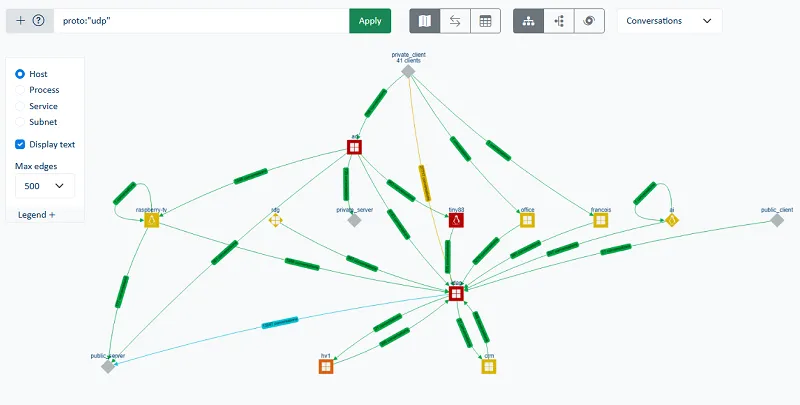
Cette centralisation de la supervision simplifie considérablement le troubleshooting, en rendant visibles les dépendances entre services sans avoir à maintenir manuellement les matrices de flux ou les cartographies statiques. Elle permet d’associer une dégradation observée sur une application à un phénomène réseau particulier, d’identifier les pics de rejets ou retransmissions TCP ainsi que de repérer une montée de latence liée à un changement de comportement d’un service tiers.
Les équipes IT peuvent ainsi identifier en quelques secondes :
- Les serveurs les plus sollicités
- Les flux entrants et sortants dominants
- Les dépendances entre applications
- Les interactions entre ressources internes et services externes
Avec une vue consolidée du trafic, la corrélation entre événements réseau et comportements applicatifs devient simple et rapide, un atout majeur pour le troubleshooting et l’optimisation continue.
3. Analyse granulaire par serveur, application et processus
La véritable difficulté de l’analyse réseau ne réside pas dans la collecte mais dans l’interprétation. Un flux TCP sur un port donné ne signifie rien tant qu’on ne sait pas quel processus l’a émis, pour quelle application il sert ni à quel moment il a été initié pour quelle durée. Les outils réseau traditionnels s’arrêtent souvent avant ce niveau de détail et laissent aux équipes Système / DevOps le soin de faire des corrélations manuelles.
ServicePilot NetTrace adopte une approche totalement différente. En observant directement la pile TCP/IP du système, il relie chaque socket à son processus parent, en identifiant l’exécutable, le chemin du binaire, l’utilisateur associé et même l’instance applicative dans un environnement multi-services. Cette capacité à contextualiser les flux au niveau du process est cruciale pour distinguer le trafic métier du trafic système. Elle permet, par exemple, de différencier un trafic généré par une base PostgreSQL, par un module de supervision ou par un composant applicatif tiers s’exécutant sur le même serveur.
Cela permet de répondre à des questions clés quand on veut analyser le comportement d'un serveur telles que :
- Quelle application consomme le plus de bande passante ?
- Quels processus génèrent un trafic inhabituel ou non autorisé ?
- Quels ports sont réellement utilisés et par quelles applications ?
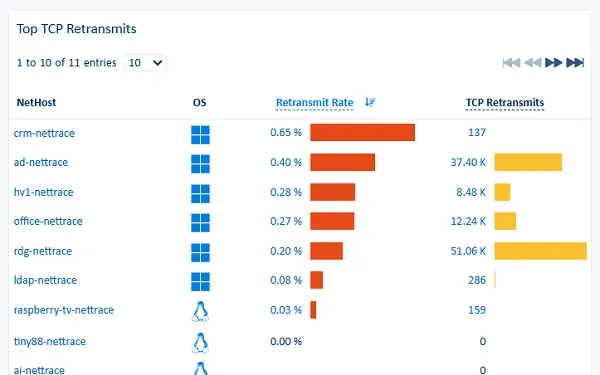
- Quels sont les taux de retransmissions, de rejets, de resets pour tel ou tel service ?
Cette granularité transforme une vue globale ("le serveur A a généré 10 Go de trafic pendant 25 minutes") en une information exploitable ("le processus B du serveur A a échangé 10 Go avec la base de données D du serveur C depuis le port E pendant 25 minutes").
NetTrace vous permet de capturer les données de paquets en live (PCAP) directement depuis le navigateur. En un seul clic, vous pouvez lancer une trace sur n'importe quel serveur et télécharger les traces des paquets pour une analyse détaillée.
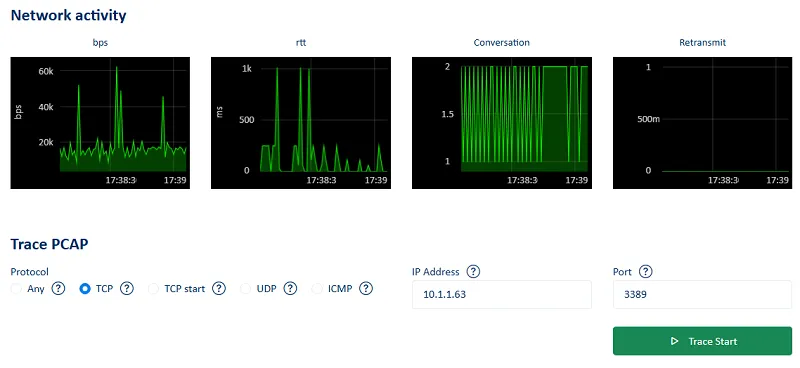
Aller jusqu'à ce niveau de détail change radicalement la compréhension du comportement réseau. On peut observer en temps réel quelles applications saturent la bande passante, quels processus établissent des connexions inattendues ou encore quelles étapes applicatives consomment le plus de ressources réseau dans un workflow donné. Dans les environnements mutualisés avec des instances ou des services parfois éphémères, cette capacité apporte une transparence indispensable pour attribuer précisément une consommation réseau à un service donné.
Résultat : un diagnostic plus rapide, une compréhension métier accrue et un renforcement naturel de la sécurité.
4. Détection automatique des anomalies et comportements suspects
L’un des enjeux majeurs de l’analyse du trafic est la détection de comportements anormaux, qu’il s’agisse d’un incident technique ou d’une activité potentiellement malveillante. Sur un serveur applicatif, une augmentation brutale du nombre de connexions sorties, un transfert massif et inhabituel ou une sollicitation excessive d’un service externe peuvent révéler une défaillance, une mauvaise configuration ou une violation des politiques de sécurité.
NetTrace intègre une logique de détection qui repose sur l’observation des variations de trafic dans le temps, la mise en évidence de déviations par rapport au comportement habituel d’un processus et l’identification de connexions qui sortent des schémas attendus. Ce mécanisme permet de signaler rapidement des flux atypiques, des communications vers des adresses jamais contactées auparavant ou des volumes qui dépassent largement les fenêtres normales de fonctionnement.
Cette capacité est essentielle pour renforcer la posture de sécurité. En observant les flux depuis le point de vue du serveur, NetTrace détecte ce que les équipements réseau ne voient pas toujours : processus légitimes qui se comportent de manière anormale, services détournés, téléchargements discrets, transferts internes inhabituels ou signaux faibles d’exfiltration. Cette approche server-centric constitue une base solide de cyber-observabilité, indispensable pour maintenir un niveau de contrôle élevé dans des environnements distribués en exponentielle croissance.
5. Historisation des données, tendances et prévisions
La supervision moderne ne se limite pas à réagir aux incidents, elle doit aussi permettre d’anticiper. L’analyse du trafic sur la durée constitue une source de données riche pour étudier l’évolution des charges, comprendre les variations saisonnières et prévoir les besoins futurs.
NetTrace conserve un historique détaillé des flux par serveur, application et processus. Ces informations ne servent pas uniquement à analyser des incidents passés : elles permettent d’identifier des cycles de trafic, de mesurer la croissance d’un service ou de repérer l’apparition progressive de nouveaux flux. L’observation de ces tendances facilite la planification de la capacité, notamment lorsqu’il s’agit de prévoir des montées en charge, de redistribuer certains services, d’évaluer l’impact d’une migration ou d'un changement de configuration.
Cette dimension analytique transforme le trafic réseau en véritable indicateur stratégique. Plutôt que d’observer ponctuellement une saturation ou une variation de charge, les équipes disposent d’une vision continue et contextualisée du comportement réseau dans le temps. Elles peuvent ainsi prendre des décisions éclairées, optimiser les ressources et adapter l’architecture avant que les limitations ne deviennent des goulots d'étranglement.
Matrice de flux dynamique : un pilier de l'observabilité moderne
La matrice de flux et l’analyse du trafic ne sont plus des outils réservés aux experts réseau. C’est aujourd’hui un élément fondamental de toute stratégie d’observabilité pour allier performance, sécurité et compréhension applicative.
La technologie NetTrace de ServicePilot fournit un niveau de précision et de contexte indispensable dans les systèmes distribués actuels. En combinant collecte multi-plateforme, visualisation consolidée, granularité applicative, détection d’anomalies et analyse historique, c'est une brique essentielle pour la supervision.
Grâce à cette approche, les équipes IT disposent enfin d’une vision claire de ce qui se passe réellement au sein des serveurs et peuvent corréler avec précision les phénomènes réseau aux comportements applicatifs. Cette compréhension fine est déterminante pour renforcer la performance, améliorer la résilience et assurer la sécurité des systèmes dans la durée.
L’observabilité du trafic système devient un outil stratégique et vos décisions gagnent en précision.
