Le futur de la supervision des serveurs : observer les flux réseau
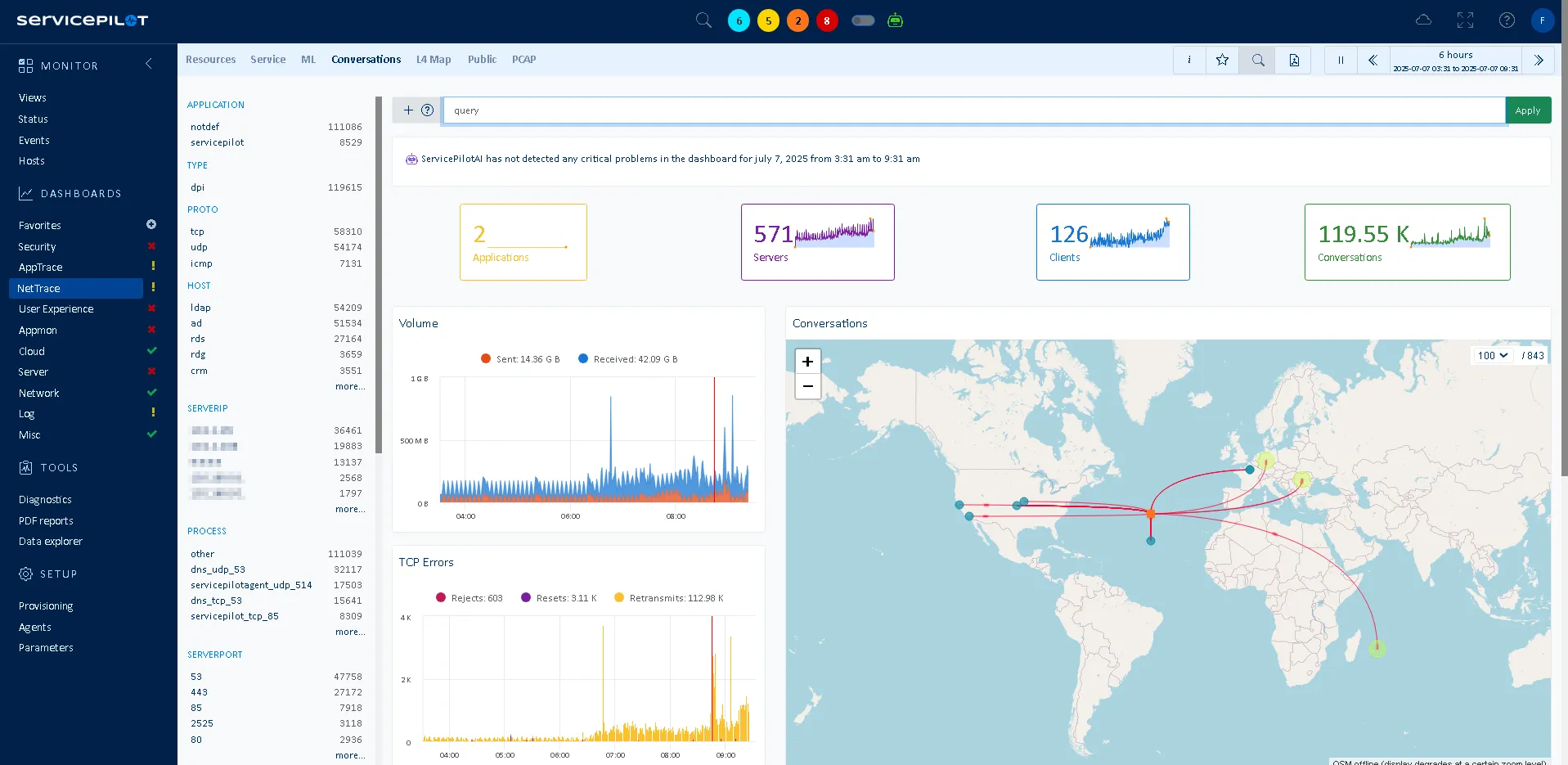
Qu'est-ce que le monitoring des flux réseaux sur les serveurs ?
NetTrace est une technologie développée par ServicePilot qui capture les flux réseau sur les serveurs Windows, Linux et IBM z/OS. La supervision des connexions réseau sur les serveurs consiste à collecter, enregistrer et analyser le trafic entrant et sortant.
Cela permet non seulement de suivre le trafic, mais aussi d'analyser les interactions entre les services, les applications, les hôtes, les clusters ou les dépendances externes dont dépendent vos services informatiques.
Pourquoi la supervision des flux réseau serveurs est cruciale ?
Les applications modernes ne fonctionnent pas de manière isolée. Elles s'appuient sur un réseau de services, d'API et d'infrastructures qui doivent tous fonctionner en harmonie. En cas de ralentissement, vos utilisateurs ne se soucient pas de savoir si le problème vient de l'application ou du réseau : ils veulent simplement qu'il soit résolu.
Mais voici le défi : les réseaux sont complexes, dynamiques et souvent opaques. Les outils de supervision traditionnels laissent des angles morts et le dépannage peut se transformer en un jeu de reproches entre plusieurs équipes informatiques.
ServicePilot NetTrace est conçu pour changer cela. En détectant automatiquement toutes les communications réseau, en mettant en évidence les points sensibles en termes de performances et en unifiant les informations sur l'ensemble de votre pile, NetTrace vous aide à identifier et à résoudre les problèmes plus rapidement.
La supervision des connexions réseaux sur les serveurs est essentielle pour assurer la performance, la fiabilité et la sécurité des systèmes. Cela offre :
- Visibilité totale : suivre les connexions réseau au niveau du serveur donne une compréhension fine de qui communique avec qui, quand et comment. Cette visibilité est essentielle pour détecter des goulots d’étranglement ou anticiper des défaillances.
- Optimisation des performances : l’analyse du trafic aide à comprendre où se situent les ralentissements pour ajuster les configurations serveurs et applications ainsi que gagner en efficacité.
- Analyse du trafic Cloud : l'Agent ServicePilot positionné sur un VPS/VDS ou une machine bare-metal offre une visibilité sur les flux réseau, même dans les environnements Cloud.
- Détection d’anomalies et sécurité : cela permet d’identifier des flux suspects comme connexions inhabituelles, tentatives d’intrusion, transferts massifs inattendus... C’est un outil clé pour renforcer la cybersécurité.
- Conformité réglementaire : dans des environnements soumis à des normes strictes (finance, santé, industrie, gouvernements…), NetTrace documente l’activité réseau pour faciliter les audits et répondre aux exigences de conformité.
Identifier les erreurs, les goulots d'étranglement et les latences des services
Imaginez ceci : un service essentiel destiné aux clients ralentit considérablement pendant les heures de pointe. Les journaux d'application n'affichent aucune erreur, mais les utilisateurs sont frustrés. Par où commencer si les mesures de base ne montrent rien ?
NetTrace fournit des tableaux de bord prêts à l'emploi qui affichent le débit, la latence et les taux d'erreur de toutes vos conversations. D'un seul coup d'œil, vous pouvez identifier les pics de retransmissions, les liaisons saturées ou les chemins lents entre les services clés. Vous remarquez peut-être que le trafic entre votre couche API et votre base de données affiche systématiquement une latence plus élevée que les autres flux. Ou qu'une seule région est à l'origine de la plupart de vos pertes de paquets. NetTrace rend ces goulots d'étranglement visibles instantanément afin que vous puissiez agir avant que les utilisateurs ne ressentent les effets négatifs. Au lieu de vous fier à votre intuition, vous effectuez un dépannage à l'aide de données et résolvez les problèmes en quelques minutes, et non en plusieurs heures.
Les serveurs, qu'ils soient Windows ou Linux, sont au cœur des opérations informatiques. L'Agent ServicePilot et une règle de Provisioning-auto permettent d'automatiser la surveillance des communications réseau afin d'aller au-delà des métriques classiques telles que Ping, SNMP, WMI, etc.
Les possibilités d'analyse sont infinies : surveillances des flux publics et des adresses IP, monitoring des transmissions des rejets par application ou par serveur... Une supervision complémentée par des statistiques sur des indicateurs clés de performance (KPI) tels que les flags TCP, les temps de réponse système / réseau ou le volume de données / de paquets offre davantage de données utiles pour le troubleshooting des incidents survenant dans des architectures complexes.
Voici quelques indicateurs importants avec leur signification :
- TCP Reset : indique la terminaison abrupte d'une connexion. Un nombre élevé de resets peut signaler des problèmes de réseau ou des attaques par déni de service. Une étude a montré que sur un réseau à grande échelle, un taux de reset supérieur à 5% peut indiquer des problèmes de réseau ou de sécurité.
- TCP Reject : refus de connexion. Une augmentation des rejets peut indiquer des tentatives d'accès non autorisées.
- TCP Retransmit : paquets retransmis. Des retransmissions fréquentes peuvent indiquer des problèmes de réseau tels que la perte de paquets ou la congestion.
- Temps de Réponse Système : surveiller le temps de réponse des serveurs pour s'assurer que les applications fonctionnent efficacement. Un temps de réponse élevé peut signaler des problèmes de performance du serveur ou une charge excessive affectant la performance des applications critiques.
- Temps de Réponse Réseau : mesurer le temps de latence pour évaluer la performance réseau. Des temps de réponse réseau élevés peuvent indiquer des problèmes de routage ou de congestion.
- Volume des données en Bytes et en Paquets : suivre le volume de données échangées pour identifier les tendances de trafic et ajuster les capacités réseau. Superviser le nombre de paquets pour détecter des anomalies dans le flux de données. Un pic de volume de données inattendu peut indiquer un téléchargement massif ou une attaque de type DDoS.
Visualiser la topologie des hosts et des applications en temps réel
Supposons que vous soyez sur le point de migrer une application vers le cloud. Tout semble parfait sur le papier, mais que se passerait-il si un service oublié dépendait encore de l'ancienne base de données sur site ?
Avec NetTrace, vous n'avez plus à vous poser la question. Dès que vous déployez l'Agent, celui-ci cartographie automatiquement toutes les communications L3 et L4 entre vos serveurs, applications et services. Le résultat est une carte topologique en temps réel de votre environnement, qui reflète le trafic réel et non des schémas obsolètes. Vous pouvez zoomer sur un service, filtrer par hôte ou observer les dépendances se mettre à jour dynamiquement à mesure que votre infrastructure évolue. Au lieu de surprises cachées, vous obtenez une vision claire : toutes les dépendances, tous les flux, en un seul endroit. Vous vous lancez dans une migration en sachant exactement ce qui ne fonctionnera plus si une connexion est coupée, et comment planifier en conséquence.
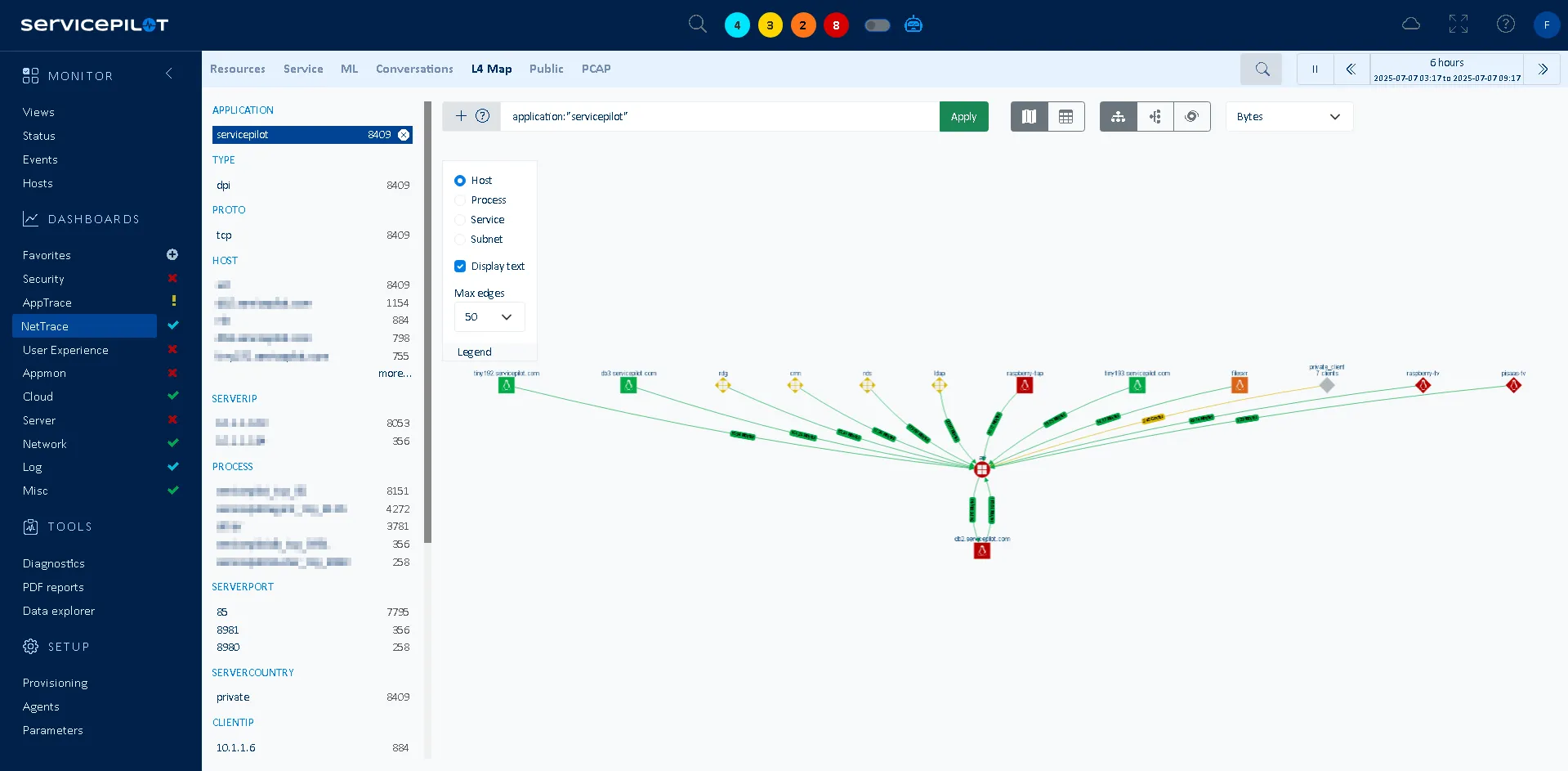
ServicePilot et sa technologie NetTrace ne se contentent pas de collecter des métriques, ils mettent en évidence les informations grâce à des interfaces visuelles et pratiques :
- Cartographie dynamique et automatisée
- Tableaux de bord en temps réel et historiques
- Exportation de fichiers PCAP
- Événements et alertes
- Rapports PDF automatisés
NetTrace offre une multitude de fonctionnalités clés qui permettent un formatage efficace des informations critiques pour la surveillance des flux des systèmes. La cartographie détaillée des liens entre les serveurs facilite l'identification et la compréhension des interactions entre les différentes applications au sein de l'environnement. Les tableaux de bord dynamiques fournissent des indicateurs essentiels tels que le volume, les erreurs par type de trafic, les protocoles utilisés et les échanges client-serveur. Enfin, les alertes en temps réel garantissent une réponse rapide aux anomalies détectées, tandis que les rapports PDF détaillés automatisent l'analyse des données pour faciliter la gestion proactive de l'infrastructure informatique.
Troubleshoot avec les traces de paquets à la demande
Parfois, les tableaux de bord ne suffisent pas. Vous avez peut-être détecté un trafic suspect ou vous souhaitez vérifier ce qui se passe sur le réseau.
NetTrace vous permet de capturer des données de paquets en live (PCAP) directement depuis le navigateur, sans quitter la plateforme. En un seul clic, vous pouvez lancer une trace sur n'importe quel serveur et télécharger les traces des paquets pour une analyse détaillée.
Par exemple, si vous constatez un trafic inhabituel provenant d'un hôte critique, vous pouvez lancer une capture et confirmer s'il s'agit d'un service mal configuré ou d'un problème plus grave. Vous bénéficiez de la visibilité approfondie des analyseurs de paquets traditionnels, intégrés de manière transparente à votre workflow de supervision.
L'avantage de cette fonctionnalité NetTrace, c'est lorsque des anomalies apparaissent, vous disposez des outils nécessaires pour les prouver, les diagnostiquer et les résoudre.
Des paquets à la topologie : supervision simplifiée pour les serveurs
En intégrant la technologie NetTrace de ServicePilot à leur stratégie d'observabilité, les équipes informatiques peuvent facilement :
- Visualiser toutes les dépendances grâce à la découverte automatique et aux cartes de topologie en direct.
- Identifier rapidement les goulots d'étranglement grâce à des tableaux de bord de performances en temps réel.
- Unifier les équipes en corrélant les informations sur les applications et le réseau.
- Approfondir leur analyse lorsque cela est nécessaire grâce à la capture de paquets intégrée.
La supervision automatique des flux ne se limite pas aux équipements réseau, elle s'étend également aux serveurs virtualisés et à ceux hébergés dans le Cloud, où les performances et la sécurité des systèmes sont critiques. La visibilité accrue du comportement du système permet d'améliorer les performances des applications, la cybersécurité et la conformité.
👉 Prêt à découvrir votre propre histoire réseau ? Commencez votre essai gratuit de ServicePilot NetTrace ou demandez une démonstration dès aujourd'hui.
