Supervision des cartes GPU Nvidia
A quoi servent les cartes GPU ?
Les GPU Nvidia jouent un rôle central dans les infrastructures modernes dédiées à l’intelligence artificielle. L'intelligence artificielle se décline en trois disciplines principales : prédictive, générative et agentique. L'IA prédictive utilise des modèles pour anticiper des événements futurs basés sur des données historiques. L'IA générative, quant à elle, crée de nouveaux contenus tels que des images, des textes ou des vidéos. Enfin, l'IA agentique se concentre sur la création d'agents autonomes capables de prendre des décisions et d'interagir avec leur environnement.
Pour déployer une solution d'IA dans un datacenter privé, plusieurs étapes sont nécessaires. Tout d'abord, il est crucial de disposer d'une infrastructure adéquate. Cela inclut l'installation de cartes GPU (Graphics Processing Unit) qui sont essentielles pour les calculs intensifs requis par les modèles d'IA. En parallèle, un logiciel comme Ollama sous Linux doit être installé pour gérer et exécuter ces modèles.
Une fois l'infrastructure prête, il est temps de choisir un Large Language Model (LLM). Ces modèles se matérialisent sous la forme de fichiers de plusieurs gigaoctets. Des options populaires incluent Mistral, Qwen ou OpenAI, disponibles en versions payantes ou gratuites. Il est important de noter que la taille du modèle en gigaoctets ne doit pas dépasser la capacité de la VRAM (Video RAM) de la carte GPU utilisée. Par exemple, si votre carte GPU dispose de 16 Go de VRAM, vous devrez choisir un modèle dont la taille n'excède pas cette limite.
Après avoir sélectionné et installé le LLM approprié, l'IA est prête à traiter des requêtes via une API REST. Cette interface permet aux applications externes d'interagir avec le modèle d'IA en envoyant des requêtes HTTP et en recevant des réponses. Cela facilite l'intégration de l'IA dans divers systèmes et services, offrant ainsi une flexibilité maximale.
Cet article détaille comment superviser efficacement les cartes GPU Nvidia, des spécificités matérielles aux métriques à collecter, et explique comment ServicePilot offre un monitoring complet sur ce périmètre.
Que sont les GPU Nvidia ?
Les GPU Nvidia se déclinent en gammes "grand public" (GeForce/RTX) et datacenter (Tesla/A100/H100, etc.). Les GPU grand public sont optimisés pour le rendu graphique en temps réel (jeux vidéo), avec pour objectif de minimiser la latence par image rendue. À l’inverse, les GPU datacenter visent le calcul intensif en parallèle. Ils traitent des lots massifs de données simultanément sans se soucier de la latence d’une opération unique, mais en maximisant le nombre d’opérations par seconde. Par exemple, l’entraînement d’un grand modèle de langage (LLM) est un travail massivement parallèle impliquant des multiplications de matrices géantes. C'est un domaine où les GPU datacenter comme les Nvidia H100 excellent en exécutant des trillions d’opérations par seconde.
Les GPU datacenter offrent également des caractéristiques matérielles avancées par rapport aux cartes grand public. Ils embarquent beaucoup plus de mémoire vidéo et supportent la mémoire à code de correction d’erreurs (ECC). Par exemple, un H100 peut contenir jusqu’à 80 Go de mémoire HBM3 contre ~24 Go GDDR6X sur une carte gaming. C'est indispensable pour fiabiliser des calculs longs et massifs car une simple inversion de bit peut corrompre un modèle entraîné pendant des semaines. Un GPU comme le H100 comporte ainsi des unités spécialisées capables de calculs en demi-précision (FP16/TF32) ou même FP8 pour accélérer drastiquement l’entraînement et l’inférence de réseaux neuronaux. Ces spécificités (mémoire massive, calcul parallèle, cœurs IA) font des GPU Nvidia des composantes incontournables des charges de travail IA modernes. Ils sont d’ailleurs omniprésents en production et apportent une puissance de calcul que les CPU ne peuvent pas fournir.
Superviser les GPU dans un environnement IA/ML et HPC (High Performance Computing) est donc vital pour détecter les goulots d’étranglement (saturation de ressources, throttling thermique, erreurs mémoire, etc.) et garantir que ces ressources onéreuses délivrent les performances attendues.
La collecte des métriques GPU
Plusieurs méthodes existent pour collecter les métriques d’un GPU Nvidia :
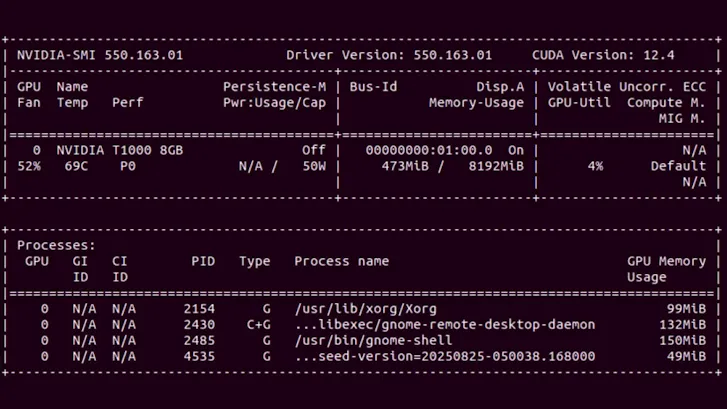
• nvidia-smi (System Management Interface) : cet utilitaire en ligne de commande, fourni avec les pilotes Nvidia, donne un instantané de l’état du GPU via les bibliothèques NVML. En tapant nvidia-smi, on obtient en temps réel l’utilisation du GPU, la mémoire consommée, la température, la puissance, etc. C’est l’outil le plus rapide pour vérifier qu’un GPU fonctionne et voir sa charge à un instant T. En revanche, nvidia-smi n’enregistre pas les métriques de façon continue ni historique. Pour une supervision continue et centralisée, il faut se tourner vers des outils dédiés.
• NVIDIA DCGM (Data Center GPU Manager) : c’est la suite logicielle officielle Nvidia composée de plusieurs outils pour la gestion et la supervision des GPU en environnement serveur. DCGM fonctionne en tâche de fond sur les nœuds GPU et expose une télémétrie fine de chaque GPU (utilisation, mémoire, température, puissance, etc.) via les bibliothèques NVML. Nvidia propose en outre un exporter Prometheus DCGM qui expose ces métriques sur HTTP pour qu’elles soient scrapées par un collecteur Prometheus ou autre agent (Telegraf, etc.). Dans Kubernetes, le déploiement NVIDIA GPU Operator intègre nativement DCGM Exporter pour publier la télémétrie des GPU et permet de construire des tableaux de bord.
Les métriques GPU importantes à superviser
Une fois la collecte en place, il est important de définir quels sont les indicateurs clés. Les GPU Nvidia fournissent de nombreux compteurs de performance et d’état, dont les principaux à superviser dans un contexte IA/ML sont :
• Utilisation GPU – le pourcentage du temps où les unités de calcul du GPU (Streaming Multiprocessors) exécutent des tâches. C’est le taux d’occupation des cœurs CUDA, indicateur principal de la charge de calcul GPU. Une utilisation proche de 100 % indique que le GPU est saturé en calcul (potentiellement un bottleneck), tandis qu’une utilisation très basse peut signaler un gaspillage de ressources si le GPU reste inactif alors qu’il y a de la demande.
• Mémoire consommée – la quantité de mémoire GPU utilisée par les applications comparée à la mémoire totale disponible. Les GPU datacenter offrent des dizaines de Go de VRAM qu’il faut surveiller pour éviter les débordements (out of memory) lors de l’inférence ou de l’entraînement de modèles lourds. La mémoire libre restante est une métrique à examiner pour anticiper les saturations de VRAM, d’autant que les LLM tiennent souvent entièrement en mémoire GPU.
• Utilisation de la mémoire GPU – le taux d’utilisation du contrôleur mémoire du GPU, soit le pourcentage de temps durant lequel la mémoire GPU est en train d’être lue ou écrite. Cela indique si le goulot d’étranglement se situe au niveau des échanges mémoire (par exemple VRAM saturée en débit, ce qui peut limiter le GPU même si les cœurs de calcul ne sont pas à 100 %). Une utilisation mémoire très élevée suggère que la bande passante mémoire du GPU est le facteur limitant (fréquent sur les modèles manipulant d’énormes tenseurs).
• Température GPU – la température du GPU, en degrés Celsius. Les GPU Nvidia peuvent monter à plus de 80°C en pleine charge. Une température qui dépasse régulièrement ~85°C est critique et peut entraîner du throttling (réduction automatique de fréquence pour éviter la surchauffe). Il convient donc de surveiller cette métrique car Nvidia indique souvent ~85°C comme seuil de danger pour la plupart des datacenter GPUs.
• Puissance consommée – la consommation électrique du GPU en watts à l’instant T. Les tâches IA étant énergivores, un GPU du type RTX/5090 gamme peut consommer plus de 600W à chaque requête. Surveiller la puissance permet de gérer la capacité électrique et thermique du datacenter, et de détecter des situations anormales (par ex. un GPU consommant plus que d’habitude pour une même charge peut indiquer un problème). Une consommation soutenue très élevée peut aussi révéler qu’une charge de travail exploite à fond le GPU et potentiellement le surmène sur la durée.
• Bande passante PCIe – la connectivité PCIe (Peripheral Component Interconnect Express) entre le GPU et le CPU. C'est un maillon critique des performances GPU, surtout dans les environnements IA et multimédia où de gros volumes de données transitent entre mémoire système et mémoire GPU. La génération PCIe (Gen3, Gen4, Gen5, etc.) et la largeur de lien (x4, x8, x16) déterminent la bande passante théorique maximale.
• Encodage vidéo – les unités matérielles dédiées à l’encodage vidéo (NVENC) et au décodage (NVDEC), utilisées dans les flux de streaming, la virtualisation GPU (VDI) ou certains pipelines multimédias IA (vision, reconnaissance d’images). Ces moteurs étant indépendants des cœurs CUDA, il est essentiel de suivre leur activité séparément. Surveiller le nombre de sessions NVENC, le débit d'images encodées (FPS) et la latence d'encodage d'une frame permettent de détecter une saturation du moteur NVENC, une compression trop complexe ou une concurrence excessive entre les flux.
• Fréquences d’horloge (clocks) – les fréquences d’horloge sont des indicateurs fondamentaux de la santé et de la performance du GPU. Il existe différentes fréquences distinctes : GPU clock, SM clock, Memory clock, etc. Ces fréquences peuvent varier dynamiquement selon la charge et la température : le GPU ajuste sa fréquence en fonction du Power Management (Dynamic Boost, Thermal Throttling, etc.). En production, il est donc capital de surveiller les variations entre la fréquence actuelle et la fréquence maximale supportée. Par exemple, une fréquence GPU ou SM qui baisse régulièrement sous la cible nominale est un signal de throttling (thermique ou énergétique). Corrélée avec la température et la puissance, cette information permet d’identifier une ventilation défaillante, une alimentation sous-dimensionnée ou une politique d’énergie trop restrictive.
Tableaux de bord et alerting intégrés
En plus de la collecte simplifiée des données, ServicePilot fournit des tableaux de bord prêts à l'emploi pour les GPU Nvidia. Le tableau de bord global offre une vue d’ensemble de la santé des GPU et présente les métriques clés de chaque carte du cluster de calcul pour comparer facilement les températures, les puissances, les utilisations moyennes de VRAM, etc. Les tableaux de bord individuels détaillés par GPU permettent de rapidement corréler les KPI d'un GPU pour identifier la cause des situations de sous-régime ou de sur-régime.
ServicePilot permet aussi de personnaliser très facilement les tableaux de bord pour combiner des widgets selon les besoins de chaque équipe. On peut filtrer et organiser les données pour créer des vues unifiées corrélant plusieurs sources de données au sein d’un même écran. Grâce à ces tableaux de bord interactifs et intuitifs, il devient aisé de faire des corrélations visuelles. Par exemple, on peut afficher côte à côte l’utilisation GPU et le débit réseau d’un service ou les métriques GPU avec les métriques CPU d’un même serveur afin d’identifier des comportements anormaux. Cette approche permet de voir en un clin d’œil l’ensemble des paramètres d’un système pour diagnostiquer rapidement les problèmes quand ils surviennent.
Côté alerting, ServicePilot se distingue par ses capacités d’alertes intelligentes et adaptatives. Les KPIs principaux disposent de seuils statiques fixes ajustables mais la plateforme offre aussi des mécanismes d’alertes avancés exploitant des analyses statistiques et du Machine Learning. En pratique, cela signifie que l’on peut activer des seuils dynamiques qui s’ajustent en fonction des tendances observées. Par exemple, le système peut établir automatiquement la "ligne de base" du taux d’utilisation GPU aux différentes heures de la journée et déclencher une alerte seulement si l’utilisation sort significativement de cette plage normale (plutôt que sur un seuil absolu arbitraire). Ce seuil auto-adaptatif évite les fausses alertes lors de pics prévisibles (batch de nuit, etc.) et met en évidence les vraies anomalies (activité inhabituelle hors profil). L’objectif est d’implémenter une détection proactive des problèmes en analysant l’évolution temporelle des métriques et leurs interactions plutôt que de simples seuils fixes.
ServicePilot priorise les alertes réellement critiques et réduit le bruit. Les algorithmes ML de détection d’anomalies repèrent automatiquement toute déviation dans les niveaux de performance ou de disponibilité habituels des services, ce qui diminue drastiquement le volume d’alertes à traiter. Les opérateurs peuvent se concentrer sur les incidents importants sans être submergés de notifications pour des variations mineures ou attendues.
Cas d'usages pour la supervision de GPU
⚡ Optimisation énergétique dans un Datacenter
Une société technologique exploitant un vaste centre de données dédié à l’entraînement de modèles d’intelligence artificielle a observé une hausse importante de ses coûts opérationnels, principalement liée à la consommation énergétique de ses GPU. Ces processeurs graphiques sont mobilisés en grand nombre pour former des réseaux neuronaux complexes, notamment dans le domaine du traitement en langage naturel (NLP).
Constat : l’analyse des données de consommation électrique a révélé que certains GPU dépensaient beaucoup d’énergie sans gain proportionnel de performance. Après investigation, l’entreprise a découvert que plusieurs modèles n’étaient pas correctement optimisés pour ses GPU, ce qui entraînait une utilisation inefficace de l’énergie. De plus, certaines unités continuaient à consommer de l’électricité même lorsqu’elles étaient partiellement inactives durant les phases de prétraitement des données.
Résultat : en identifiant ces inefficacités, l’entreprise a pu réajuster ses modèles et ses charges de travail, réduisant ainsi significativement la dépense énergétique tout en améliorant la productivité de ses GPU.
🚗 Traitement vidéo pour les véhicules autonomes
Une entreprise développant des véhicules autonomes s’appuie sur des GPU pour analyser en temps réel les flux vidéo de ses caméras embarquées. Ces calculs permettent la détection d’objets, la planification de trajectoire et la prise de décision instantanée.
Défi : le traitement en temps réel exige une gestion rigoureuse de la mémoire graphique. Un dépassement de la capacité mémoire peut provoquer des retards critiques dans des opérations comme la reconnaissance d’obstacles ou le maintien dans la voie, compromettant la sécurité du véhicule.
Solution : en surveillant précisément l’utilisation de la mémoire GPU, les ingénieurs ont pu anticiper les pics de charge et adapter dynamiquement les traitements. Cette supervision continue garantit la stabilité des performances et la fiabilité des décisions du système embarqué, même dans des environnements complexes et dynamiques.
🏥 Centre de recherche et imagerie médicale
Dans un centre de recherche médicale, une équipe utilise des GPU pour entraîner un modèle de segmentation de tumeurs sur des images 3D issues de scanners CT et IRM. Ces volumes d’images très détaillés sollicitent intensément la mémoire graphique.
Problème : avec l’augmentation du volume des données, les chercheurs ont été confrontés à des erreurs d’« Out of Memory » (OOM) causées par un espace de tampon d'images insuffisant sur les GPU. Les images 3D haute résolution saturant la mémoire, le processus d’entraînement était souvent interrompu retardant l’avancement du projet.
Approche adoptée : les chercheurs ont implémenté une stratégie de sous-échantillonnage et d’apprentissage par patchs, en découpant les images en sections plus petites traitées individuellement. Cette optimisation a considérablement réduit la consommation mémoire, permettant des entraînements continus et stables sans compromettre la précision du modèle.
🌦️ Recherche climatique et simulations météorologiques
Un institut de recherche climatique exploite un cluster de GPU pour réaliser des simulations météorologiques à grande échelle. Ces modèles nécessitent d’importants calculs parallèles afin de prédire avec précision l’évolution des conditions atmosphériques.
Observation : les chercheurs ont remarqué que la fréquence des multiprocesseurs (SM clock) restait élevée alors que l’utilisation globale du GPU demeurait faible. L’analyse a révélé un goulot d’étranglement lié à la mémoire : le GPU attendait en permanence les transferts de données depuis la mémoire principale ou le bus PCIe, limitant l’exploitation de sa puissance de calcul.
Optimisation : en révisant les schémas d’accès à la mémoire et en fluidifiant les transferts de données, l’équipe a réduit les temps d’attente et a amélioré l’efficacité du traitement parallèle. Cette optimisation a permis d’accélérer les simulations tout en maximisant l’utilisation des ressources matérielles disponibles.
Monitoring clé-en-main des GPU Nvidia avec ServicePilot
La supervision des GPU Nvidia ne se limite plus à collecter quelques compteurs matériels : elle représente désormais un enjeu d’observabilité stratégique pour toutes les infrastructures modernes d’IA, de calcul haute performance ou de rendu graphique. Entre les charges massivement parallèles, les variations thermiques rapides et les comportements dynamiques liés à la gestion d’énergie, un GPU est un composant vivant dont la performance peut évoluer rapidement. Sans un suivi précis et continu, les équipes perdent vite la visibilité sur ce qui conditionne réellement la stabilité et la performance de leurs workloads.
L’approche clé-en-main de ServicePilot transforme la supervision des GPU en un service d’observabilité complet et facile à déployer. Les DevOps, ingénieurs système ou data engineers peuvent ainsi surveiller leurs ressources Nvidia sans passer des heures à maintenir des dashboards ou des scripts maison. Chaque GPU devient un élément pleinement intégré de l’écosystème de supervision, visible, analysé et corrélé dans la même interface que le reste de l’infrastructure.
ServicePilot offre une observabilité moderne des GPU avec : une intégration simplifiée et automatique, une analyse intelligente des KPI ainsi qu'une vision unifiée de la performance matérielle. Pour toute organisation exploitant la puissance des GPUs Nvidia, c’est la garantie d’une supervision fiable, évolutive et immédiatement exploitable.
👉 Besoin de visibilité sur les performances de vos GPU Nvidia ? Commencez votre essai gratuit de ServicePilot ou demandez une démonstration dès aujourd'hui.
