Alertes
ServicePilot peut alerter les utilisateurs dès qu'un événement important se produit. Il peut également générer des alertes de manière proactive si une tendance est susceptible de dépasser un seuil dans le futur. Les alertes peuvent également être retenues si l'on prévoit qu'un événement se dissipera sans aucune intervention.
Par défaut, ServicePilot présentera toutes les données via son interface web mais aucune alerte ne sera générée. Pour ajouter des alertes, de nouvelles Policies d'Alerte doivent être configurées. Notez que les Policies d'Alerte sont toutes indépendantes les unes des autres. Il faut faire attention lors de la création de nouvelles alertes afin d'éviter de générer des alertes chevauchantes qui pourraient alerter les utilisateurs du même problème à plusieurs reprises.
Pour ajouter des Policies d'Alerte, consultez la documentation Policies.
Chaque alerte a trois composantes :
- Une Condition définie ce qui déclenchera l'alerte
- Un Délai indique si l'alerte doit être retardée pendant un certain temps ou un certain nombre d'événements similaires
- Une Action est prise lorsque les conditions d'alerte sont respectées et que le délai est expir
Condition d'alerte
Pour qu'une alerte se déclenche, certaines conditions doivent être satisfaites. Ces conditions sont associées aux événements que ServicePilot détecte.
| Type de Condition | Événement |
|---|---|
| Ressources | Changement de statut d'une ressource au cours d'une période définie. |
| Objets | Changement de statut d'un objet au cours d'une période définie. Les objets déclenchant l'alerte peuvent être filtrés par nom, classe, vue et statut d'acquittement. |
| Query | Une requête Lucene et un seuil sont exécutés toutes les minutes. |
| Vues | Changement de statut d'une vue pendant une période définie. Les vues déclenchant l'alerte peuvent être filtrées par nom, classe et statut d'acquittement. |
| Indicateurs | Changement de statut d'un indicateur individuel au cours d'une période définie. Les indicateurs déclenchant l'alerte peuvent être filtrés par nom, nom d'objet, classe d'objet, vue et statut d'acquittement. |
| NDR | Un événement de détection et de réponse du réseau (NDR) a été détecté. |
| SNMP Trap | Réception par ServicePilot d'un trap ou notification SNMP pendant une période définie. Les traps peuvent être catégorisés à l'aide des règles de catégorisation SNMP Trap avant d'être filtrés par nom de règle, catégorie de règle, message de règle, sévérité de règle, OID d'entreprise, types générique et spécifique, adresses IP de l'expéditeur et de l'agent. Notez que si un trap est rejeté et n'est donc pas stocké dans la base de données ServicePilot, la Policy d'Alerte ne sera pas appliquée. |
| Syslog | Réception d'un message syslog pendant une période définie. Les syslogs peuvent être filtrés par adresse IP source, gravité, facility, host, description, tag, PID, Msg ID et data. |
Note : les opérateurs peuvent marquer les statuts d'alerte des ressources, vues et objets comme étant acquittés. Les éléments acquittés peuvent alors être inclus ou exclus des conditions d'alerte et de la section "statut" de la supervision.
Note : Anomalies de ressources - Les objets changent d'état en fonction des seuils et de la disponibilité. Il est possible d'ignorer les alertes relatives aux objets en se basant sur des données historiques qui déterminent si l'état de la ressource de l'objet est considéré comme une anomalie.
Condition Ack
Lors de la création de Policies d'Alerte avec des conditions Objets, Vues ou Indicateurs, le champ Ack peut être défini pour inclure ou exclure les événements acquittés. Il existe trois options pour le champ Ack :
| Ack | Utilisation |
|---|---|
| Ignore | Ignorer le statut Ack de l'élément |
| Ack | Inclure seulement les éléments qui ont des problèmes de performance ou de disponibilité qui ont déjà été acquittés |
| Not Ack | Inclure seulement les éléments qui n'ont pas été acquittés |
Délai d'alerte
Bien que toutes les conditions d'une alerte puissent être satisfaites, l'action d'alerte ne sera pas exécutée tant que le délai n'aura pas expiré.
| Type de délai | Utilisation |
|---|---|
| Sans délai | L'action sera prise dès que les conditions seront satisfaites. |
| Action et ignore Condition pendant x Minutes | L'action sera prise dès que les conditions seront satisfaites. Toutefois, l'action ne sera plus réalisée pendant la durée spécifiée, même si les conditions sont de nouveau satisfaites. Cette option est utile lorsque les conditions sont succeptibles de se produire de façon répétée et que vous souhaitez n'être alerté qu'une seule fois. |
| Action après x Minutes si Condition toujours vraie | L'action sera retardée de la durée spécifiée. Ce n'est que si les conditions sont toujours vraies après ce délai que l'action aura lieu. Cette option est utile lorsque les conditions peuvent se produire puis se rétablir d'elles-mêmes. Si le problème persiste, l'action sera déclenchée. |
| Action après x occurrences de la Condition pendant y Minutes | L'action ne sera déclenchée que si elle se produit un nombre de fois pendant la durée spécifiée. Cette option est utile pour des évènements tels que des tentatives de connexion échouées, reçus par syslog, qui indiqueraient une tentative de violation de la sécurité. |
Action d'alerte
Une fois les conditions satisfaites, et un éventuel délai expiré, différentes actions peuvent être prises.
| Type de Condition | Événement |
|---|---|
| Envoyer un email | |
| Webhook | Envoyer une requête web GET ou POST. Cela permet d'intégrer des systèmes de ticketing ou des plateformes de messagerie comme Microsoft Teams. Voir les exemples pour plus de détails. |
| UDP | Envoyer un paquet UDP. Si le paquet UDP est correctement formaté et envoyé au port correct, cela peut être défini comme un message syslog |
| Trap | Envoyer un Trap SNMP |
Note : les actions Email regroupent toutes les alertes du même type toutes les minutes et envoient un e-mail récapitulatif contenant tous les changements. Pour envoyer des courriels individuels par alerte, choisissez l'option Non groupé et spécifiez l'objet et le corps du texte de l'email à utiliser.
Variables d'alerte
Lorsqu'une alerte est déclenchée, certaines informations sont stockées dans des variables et peuvent ensuite être utilisées dans l'action d'alerte. Un sujet d'email peut par exemple contenir le nom de l'objet qui a déclenché l'alerte ou un message UDP syslog peut indiquer l'heure à laquelle l'événement s'est produit.
Certaines variables sont communes à toutes les conditions d'alerte tandis que d'autres variables diffèrent selon les conditions utilisées. Si par exemple vous avez besoin de la valeur de l'indicateur qui a dépassé son seuil, celle-ci ne sera disponible que pour les alertes ayant une condition de type Indicateurs.
Des informations communes sont collectées pour toutes les alertes.
| Variable | Contenu |
|---|---|
{DATE} |
Date d'alerte basée sur l'heure locale du serveur ServicePilot |
{TIME} |
Heure d'alerte basée sur l'heure locale du serveur ServicePilot |
{DATEUTC} |
Date d'alerte en UTC |
{TIMEUTC} |
Heure d'alerte en UTC |
{BASEURL} |
URL de base du serveur ServicePilot |
{LOCALIP} |
Adresse IP du serveur ServicePilot |
{LOCALWEBPORT} |
Port Web du serveur ServicePilot |
Ces variables ne sont disponibles qu'en fonction de la condition de la Policy d'Alerte.
| Condition | Variable | Contenu |
|---|---|---|
| Ressources, Vues, Objets, Indicateurs | {RESOURCE} |
Le nom de la ressource |
{PACKAGE} |
Le type de package de la ressource | |
{TECHNOLOGY} |
Le type de package ou la première partie du nom du package | |
{TAGS} |
Toutes les valeurs des tags associés à la ressource | |
{TAG_1} ... {TAG_5} |
La première à la cinquième valeur de la tag associée à la ressource | |
{STATUS} |
Le statut actuel de la ressource, de la vue ou de l'objet en tant que caractère unique (?, -, 1, 2, 3, +) | |
{STATUSBADGE} |
Le statut actuel de la ressource, de la vue ou de l'objet sous forme de texte formaté HTML (?,-,1,2,3,+) | |
{STRSTATUS} |
Le statut actuel de la ressource, de la vue ou de l'objet en tant que texte (UNKNOWN, UNAVAILABLE, MINOR, MAJOR, CRITICAL, OK) | |
{OLDSTATUS} |
Le statut précédent de la ressource, de la vue ou de l'objet en tant que caractère unique (?, -, 1, 2, 3, +) | |
{OLDSTATUSBADGE} |
Le statut précédent de la ressource, de la vue ou de l'objet sous forme de texte formaté HTML (?,-,1,2,3,+) | |
{STROLDSTATUS} |
Le statut précédent de la ressource, de la vue ou de l'objet en tant que texte (UNKNOWN, UNAVAILABLE, MINOR, MAJOR, CRITICAL, OK) | |
{DURATION} |
La durée depuis laquelle la vue ou l'objet est dans l'état actuel | |
{PROBLEMNOTE} |
Une note relative au problème, saisie par un opérateur | |
{TEXT} |
un texte expliquant le dernier changement d'état d'une vue ou d'un objet | |
{DESCRIPTION} |
Le contenu du champ de description de la ressource | |
{NOTE} |
Le contenu du champ Note | |
| Vues, Objets, Indicateurs | {CLASS} |
Le type de vue ou d'objet |
{VIEW} |
Le nom de la vue | |
{PARENTVIEW} |
La vue parente de celle qui a déclenché l'alerte | |
{OBJECT_1} ... {OBJECT_5} |
Le contenu de la vue ou les constantes d'objet 1 à 5 | |
{VIEW_0} ... {VIEW_9} |
Le nom des vues de niveau 0 à 9 dans lesquelles se trouve cette vue, 0 correspondant à la vue MAIN | |
| Ressources, Objets, Indicateurs | {ANOMALY} |
Si cette alerte est basée sur une anomalie détectée, ! est renvoyé dans ce champ. Lorsque l'option HTML est activée, ce champ inclura le formatage HTML |
| Objets, Indicateurs | {OBJ} |
Le nom de l'objet |
{IP} |
L'adresse IP de l'objet | |
{HOST} |
Le FQDN ou l'adresse IP de l'objet, selon les méthodes de résolution de noms disponibles | |
{AGENTNAME} |
Nom de l'Agent ServicePilot fournissant des données à l'objet | |
| Indicateurs | {INDICATORSTATUS} |
Le statut actuel de l'indicateur en tant que caractère unique (?, -, 1, 2, 3, +) |
{INDICATOROLDSTATUS} |
Le statut précédent de l'indicateur en tant que caractère unique (?,-,1,2,3,+) | |
{INDICATORNAME} |
Le nom de l'indicateur | |
{INDICATORVALUE} |
La valeur actuelle de l'indicateur | |
| Syslog | {TIMESTAMP} |
Le timestamp trouvé dans le syslog |
{IP} |
L'adresse IP depuis laquelle le syslog a été reçu | |
{HOST} |
Le host trouvé dans le syslog | |
{PID} |
Le PID trouvé dans le syslog | |
{TAG} |
Le Tag trouvé dans le syslog | |
{TEXT} |
Le texte du syslog | |
{DESCRIPTION} |
Le texte du syslog après que tous les éléments nommés aient été analysés | |
{FACILITY} |
Facility syslog | |
{SEVERITY} |
Gravité syslog | |
{MSGID} |
L'ID du message trouvé dans le syslog | |
{DATA} |
Les données structurées trouvées dans le syslog | |
| SNMP Trap | {TRAPNAME} |
Le nom de la règle de trap |
{TRAPCATEGORY} |
La catégorie associée à la règle de trap | |
{TRAPSEVERITY} |
La gravité associée à la règle de trap | |
{TRAPMESSAGE} |
Le message associé à la règle de trap | |
{TRAPIPSENDER} |
L'adresse IP de l'expéditeur du trap | |
{TRAPIPAGENT} |
L'adresse IP de l'agent SNMP qui a envoyé le trap | |
{TRAPALLOIDVALUES} |
L'ensemble des valeurs OID du trap reçu | |
{TRAPOID1} ... {TRAPOID20} |
Le nom de la variable OID du trap de 1 à 20 | |
{TRAPVALUE1} ... {TRAPVALUE20} |
La valeur de la variable OID du trap de 1 à 20 | |
| NDR | {TIMESTAMP} |
Heure à laquelle l'événement NDR a été détecté |
{PROTO} |
Le protocole (TCP, UDP, ICMP) de l'événement NDR | |
{SRCAGENT} |
L'Agent ServicePilot qui détecte la source du trafic de l'événement NDR | |
{SRCIP} |
L'adresse IP source du trafic de l'événement NDR | |
{SRCHOST} |
Nom de l'hôte source du trafic d'événements NDR | |
{SRCCOUNTRY} |
Pays d'origine du trafic de l'événement NDR | |
{SRCPROCESS} |
L'ID du process source du trafic de l'événement NDR | |
{DSTAGENT} |
L'Agent ServicePilot détectant la destination du trafic de l'événement NDR | |
{DSTIP} |
L'adresse IP de destination du trafic de l'événement NDR | |
{DSTPORT} |
Le port de destination du trafic de l'événement NDR | |
{DSTHOST} |
Nom de l'hôte de destination du trafic d'événements NDR | |
{DSTCOUNTRY} |
Pays de destination du trafic de l'événement NDR | |
{DSTPROCESS} |
L'ID du process de destination du trafic de l'événement NDR | |
{MODEL} |
Le modèle qui déclenche l'événement NDR | |
{ATTACK} |
Le type d'attaque détecté par le modèle | |
{SCORE} |
Le score de certitude de l'événement NDR | |
| Query | {COLLECTION} |
La collection de données ServicePilot à interroger |
{QUERY} |
La requête Lucene effectuée | |
{OPERATOR} |
L'opérateur de seuil utilisé pour comparer la requête avec le seuil | |
{THRESHOLD} |
Valeur seuil utilisée pour tester la requête | |
{VALUE} |
La valeur retournée par la requête | |
| Délai pas "Sans délai" | {CORRID} |
L'ID de corrélation unique au contexte de l'alerte qui a été utilisé pour vérifier les conditions après le délai spécifié |
{WINDOW} |
La fenêtre de temps pendant laquelle les conditions d'alerte se sont vérifiées avant de déclencher l'alerte | |
{NBEVENTS} |
Le nombre d'évènements correspondant aux conditions d'alerte qui déclenchent l'alerte |
Acquitter les changements de statut
Lorsque des éléments dans ServicePilot changent de statut et deviennent non disponibles ou ont un problème de performance, les objets, vues et ressources refléteront ce problème. Il est possible d'acquitter le problème afin qu'il puisse être ignoré dans les vues Statut et dans les conditions d'alerte. Le fait d'acquitter un problème ne modifiera pas son statut ou ne masquera pas le problème, mais une note sera visible en regard de l'élément acquitté.
Si le problème est résolu et que les éléments deviennent disponibles et nominaux, l'acquittement disparaîtra. Cela peut être un problème pour les éléments qui changent continuellement entre le statut nominal et un mauvais statut, car un acquittement ne sera pas maintenu. Dans ce cas, une Note peut être ajoutée à la place car elle ne sera pas supprimée automatiquement.
Accéder à "Ack/Note" d'un objet à partir de la cartographie
| 1. En tant qu'utilisateur avec au moins les privilèges opérateur, naviguez dans la hiérarchie de Vue jusqu'à l'objet que vous souhaitez acquitter/noter puis cliquez dessus |
| 2. Cliquez sur le bouton Ack ou Note |
Accéder à "Ack/Note" d'une vue à partir de la cartographie
| 1. En tant qu'utilisateur avec au moins les privilèges opérateur, naviguez dans la hiérarchie de Vue jusqu'à l'intérieur de la vue que vous souhaitez acquitter/noter |
| 2. Cliquez sur l'icône Loupe |
| 3. Cliquez sur le bouton Ack ou Note |
Accéder à "Ack/Note" à partir des listes de statut
| 1. En tant qu'utilisateur avec les privilèges opérateur, naviguez jusqu'à Statut |
| 2. Sélectionnez Ressource, Objet ou Vue dans le sous-menu Statut en fonction du composant que vous souhaitez acquitter/noter |
| 3. Sélectionnez un ou plusieurs éléments à acquitter ou noter et cliquez sur le bouton ack vert ou le bouton note bleu |
Filtrer des listes de statut
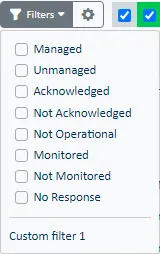
Dans les listes de Statut, vous pouvez trouver des éléments en fonction d'un certain nombre de critères de filtrage. La liste des filtres disponibles dépend de la liste de statuts (Ressource, Objet, Vue) sélectionnée :
| Filtre | Définition |
|---|---|
| Managed | Afficher les éléments qui ne sont pas marqués comme non gérés. Les opérateurs peuvent marquer manuellement les éléments comme non gérés pour arrêter de rapporter le statut ou aussi arrêter de collecter des données. |
| Unmanaged | Afficher les éléments qui sont actuellement marqués comme non gérés. Les opérateurs peuvent marquer manuellement les éléments comme non gérés pour arrêter de rapporter le statut ou également arrêter de collecter des données. |
| Acknowledged | Afficher les éléments qui ont des problèmes de performance ou de disponibilité et qui ont été marqués d'un Ack. |
| Not Acknowledged | Afficher les éléments qui n'ont pas été marqués d'un Ack. |
| Not Operational | Afficher les éléments qui clignotent, indiquant qu'un Agent ServicePilot ne rapporte pas certaines données pour la ressource. |
Exemples d'Alerting
Pour recevoir des emails lorsqu'un ping ne répond plus, une Policy de type Alerte est nécessaire :
| 1. Ajouter une nouvelle Policy de type Alerte | |
2. Définir un nom de Policy d'alerte correspondant. Par exemple : alert_ping_no_response_email |
|
3. Cocher la case Appliquer cette Policy à l'ensemble de la configuration pour que la Policy s'applique sur tous les objets Ping de la configuration |
|
| 4. Dans l'onglet Condition, définir le type de condition sur Objets | |
| 5. Définir le From status sur toutes les couleurs sauf le rouge | |
| 6. Définir le To status seulement sur le rouge | |
7. Définir les Classes filtrées sur Ping |
|
| 8. Dans l'onglet Action, définir le type d'Action sur email | |
| 9. Définir les adresses de l'expéditeur et du/des destinataires (séparés par un point-virgule) | |
| 10. Si choix d'envoi d'emails non groupés, cocher la case Non groupé | |
11. Si choix d'envoi d'emails non groupés, définir le Sujet. Par exemple : (ServicePilot) Le Ping de {OBJ} ne répond plus |
|
12. Si choix d'envoi d'emails non groupés, définir le Message. Par exemple : Le Ping de {OBJ} ne répond pas à {DATE} {TIME} |
|
| 13. Sauvegarder la nouvelle Policy | |
Cette alerte peut être envoyée pour une partie seulement de la configuration. Vous pouvez appliquer cette Policy à une vue ou à un certain nombre de ressources individuellement.
Teams peut recevoir et poster des messages sur un canal à l'aide d'une URL créée pour envoyer des webhooks. Commencez par créer l'URL dans Microsoft Teams, puis définissez correctement l'URL et le corps POST dans une alerte ServicePilot.
| 1. Ajouter une nouvelle Policy de type Alerte | |
2. Définir un nom de Policy d'alerte correspondant. Par exemple : alert_teams_channel |
|
| 3. Définissez la Condition requise | |
| 4. Dans l'onglet Action, réglez le type d'action sur Webhook | |
| 5. Définissez la Méthode sur Post | |
| 6. Définissez les données Webhook à l'aide d'une définition JSON AdaptiveCard | |
| 7. Testez le nouveau Webhook | |
| 8. Sauvegarder la nouvelle policy d'alerte | |
Example Microsoft Teams webhook body:
{
"type": "message",
"attachments": [{
"contentType": "application/vnd.microsoft.card.adaptive",
"contentUrl": null,
"content": {
"$schema": "http://adaptivecards.io/schemas/adaptive-card.json",
"type": "AdaptiveCard",
"version": "1.2",
"body": [{
"type": "TextBlock",
"text": "ServicePilot object unavailable: {OBJ}"
}
]
}
}
]
}
Pour obtenir des notifications lorsqu'un volume de disque dur dépasse le seuil majeur ou critique d'utilisation de l'espace, il faut ajouter une nouvelle Policy de type Alerte :
| 1. Ajouter une nouvelle Policy de type Alerte | |
2. Définir un nom de Policy d'alerte correspondant. Par exemple : alert_disk_space_usage_high |
|
3. Cocher la case Appliquer cette Policy à l'ensemble de la configuration pour que la Policy s'applique sur tous les objets Server Disk de la configuration |
|
| 4. Dans l'onglet Condition, définir le type de condition sur Indicateurs | |
| 5. Définir le From status sur gris, vert et bleu | |
| 6. Définir le To status sur jaune et orange | |
7. Définir le Classes filtrées sur Server Disk |
|
8. Définir le Indicateurs filtrés sur Space Usage |
|
| 9. Sauvegarder la nouvelle policy d'alerte | |
Lorsque la condition est définie sur le type Indicateurs, le nom de l'indicateur et les valeurs actuelles peuvent être utilisés dans l'action. Par exemple: Alerte {STRSTATUS} sur disque: L'utilisation de {OBJ} est à {INDICATORVALUE}
Envoyer un message syslog au format RFC5424 lorsqu'un objet devient critique.
| 1. Ajouter une nouvelle Policy de type Alerte | |
2. Définir un nom de Policy d'alerte correspondant. Par exemple : alert_object_critical |
|
| 3. Dans l'onglet Condition, définir le Du statut sur tous les objets cochés sauf critiques et le Au statut sur tous les objets non cochés sauf critiques | |
| 4. Dans l'onglet Action, définir le type d'action sur UDP | |
5. Définir le Port UDP sur 514 |
|
6. Définir le Message UDP sur <10>1 {DATEUTC}T{TIMEUTC}Z servicepilot.company.com servicepilot - - [criticalObjAlert@23098 object="{OBJ}" class="{CLASS}" problem="{PROBLEMNOTE}"] Critical Object Alert for {OBJ}, Problem: {PROBLEMNOTE} |
|
| 7. Sauvegarder la nouvelle Policy d'alerte | |
Pour obtenir une alerte en dehors des heures de bureau, commencez par créer une période définissant les plages horaires en dehors des heures de bureau. Incluez ensuite cette période dans la nouvelle Policy de type alerte.
1. Ajoutez une nouvelle Période de temps avec un nom comme En dehors des horaires 1 |
|
2. Définir les Plages à 00:00 - 09:00 et 18:00 - 23:59 de Monday à Friday |
|
| 3. Sauvegarder la nouvelle Période | |
4. Ajouter une seconde Période de temps avec un nom comme En dehors des horaires 2 |
|
5. Définir les Plages à 00:00 - 23:59 pour Samedi et Dimanche |
|
| 6. Sauvegarder la nouvelle Période | |
| 7. Ajouter une nouvelle Policy de type Alerte | |
8. Définir le nom de la Policy d'alerte. Par exemple : alerte_ooh_site_ressource_non_disponible |
|
| 9. Dans l'onglet Condition, définir le type de condition sur Ressources | |
| 10. Définir la Période d'alertes sur `En dehors des horaires 1 | En dehors des horaires 2` |
| 11. Définir le From status sur toutes les couleurs sauf le rouge | |
| 12. Définir le To status sur le rouge seulement | |
| 13. Définir l'action | |
| 14. Sauvegarder la nouvelle Policy | |
15. Appliquer la nouvelle Policy sur la vue Sites pour affecter toutes les ressources contenues dans cette vue et dans ses sous-vues. |
|
