Root Cause Analysis (RCA) for Optimized IT Performance
Minimizing Incident Resolution Time with Effective RCA
Applications are more dynamic and complex than ever. They often rely on intricate dependencies that go beyond the capacity of traditional monitoring tools for analysis. We integrate the power of AI to detect cause-effect relationships in modern app environments.
Consider a large financial institution with a multitude of interconnected applications running at the same time. A sudden drop in the performance of their transaction processing system might lead to significant losses. With our AI-enabled RCA, they can speed up the issue's root cause identification to minimize the potential financial impact.
- With our RCA, you can quickly identify what is affecting the application performance
- It will reduce downtime leading to better productivity and user satisfaction
Streamlining Alerts for Efficient Incident Management
We use ML algorithms for automatic detection of any anomaly in availability or service performance levels. Alert volume is reduced which allows a better focus on urgent incidents.
Imagine an IT company dealing with a high volume of daily alerts but most of them being non-critical. It causes operator fatigue and decreases efficiency. With our alert management system will drastically reduce the volume of alerts allowing operators to concentrate on truly critical issues.
- By reducing the amount of alerts that operators have to deal with, they can quickly identify service problems and fix them
- It helps IT operators to work more efficiently and resolve incidents faster
Automated analysis through Machine Learning
Our ML feature performs distinct analysis on each monitored resource. Automated thresholds can be set based on ML algorithms to issue essential alerts for monitoring activities, transactions and detect unusual events.
Let's consider an international e-commerce platform that gets seasonal traffic fluctuations. They can automate analysis to monitors their web servers, create dynamic thresholds that adapt to the changing traffic and receive alerts only when real unusual events occur.
- The automation of this analysis helps with incident detection
- Applications and IT systems are enhanced and potential service disruptions are reduced
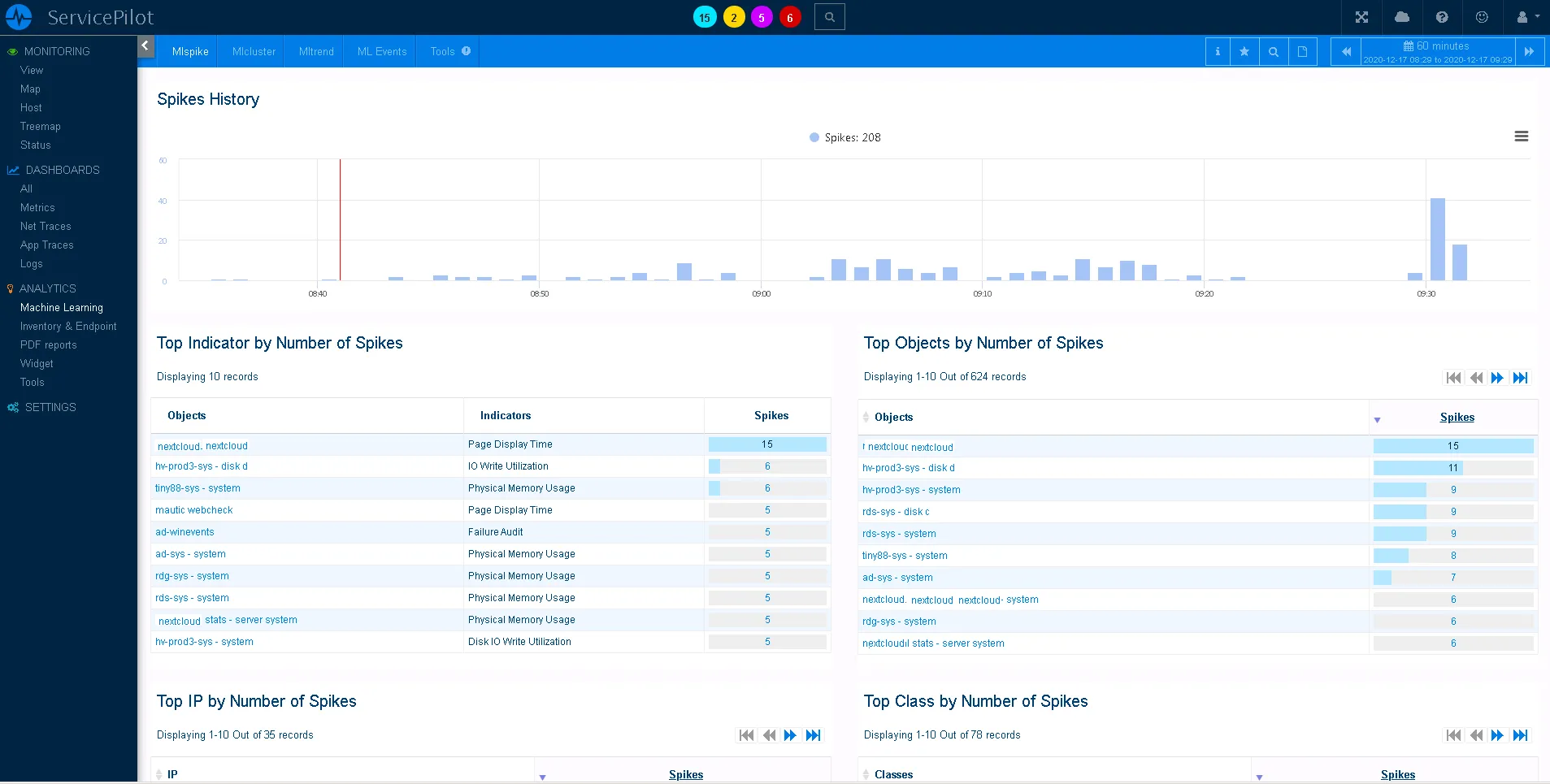
Enhanced Incident Understanding with Root Cause Visualization
Our solution offers a refined list of events and alerts, providing a drill-down view of probable causes behind any given incident. This feature presents a list of resources which could contribute to the incident and a cause score for the actual origin of the failure.
Let's imagine a SaaS company dealing with frequent web app crashes. Our root cause visualization can help them identify a problematic database query that's causing the crashes, allowing for a prompt resolution.
- With this feature, troubleshooting production issues is simpler and more efficient
- It leads to a quick incident resolution and improved service reliability
Free installation in
a few clicks
SaaS Plateform
- No on-premise software setup, servicing and configuration complexity
- Instant setup, complete and pre-configured to ensure robust monitoring
OnPremise Plateform
- Contracts and commitments over time ( > 1 year)
- Performance, Data Storage and Infrastructure Management
- 2 additional solutions: VoIP and Mainframe monitoring
