Problem Management and Root Cause Analysis
What is alert fatigue?
Alert fatigue is the phenomenon whereby an excessive volume of alerts (often false positives or low priority) desensitizes monitoring teams, leading to ignored alerts, delayed responses or missed incidents. Operators become overwhelmed by repeated and irrelevant notifications issued by monitoring and security tools. The result is a decline in vigilance and an increased risk of human error.
How does this happen?
- Too many simultaneous or frequent alerts
- False positives and low-priority alerts that are not filtered out
- Lack of prioritization and clear escalation in operational procedures
These factors lead to desensitization and slow responses to truly critical alerts. The concrete consequences for organizations are:
- Missed critical alerts and increased resolution times
- Despondence and demoralizing of monitoring teams
- Increased operational risk and security
Reducing MTTR and alert fatigue in IT systems
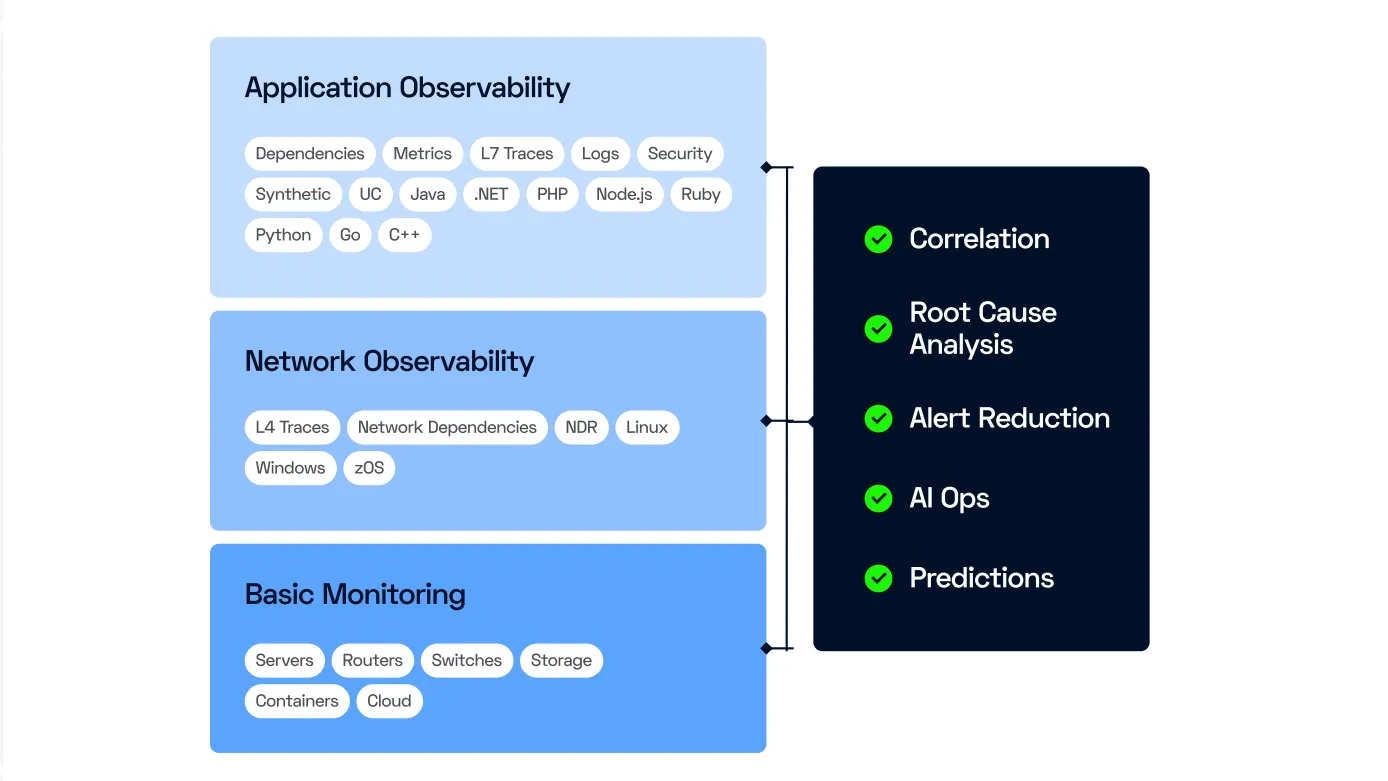
In modern environments with applications based on microservices architectures and distributed hybrid or cloud-hosted infrastructures, effective problem management and root cause analysis (RCA) are crucial.
These complex architectures require in-depth monitoring to quickly identify incidents and their underlying causes. This helps prevent cascading incidents, minimize downtime and ensure optimal performance.
That's why ServicePilot v12 is introducing a new “Problems” concept that improves incident management and root cause analysis. This feature allows you to intelligently correlate alarms and identify root causes with greater accuracy.
Fundamental concepts: incident, anomaly, problem, root cause
An apparent incident (e.g. slow service) may be the result of a deeper problem (infrastructure, dependency, database, application error, etc.). Without intelligent correlation, there is a risk of an avalanche of redundant alerts (causing “alert fatigue”), with an increase in noise that is actually detrimental. The idea is to group together everything that belongs to the same “problem.”
Incident/Alert: Any observable behavior with thresholds (slow response, error, saturation, crash, etc.). When a significant incident is identified, it is flagged with a critical or unavailable status in ServicePilot. An critical status indicates significantly degraded performance, while an unavailable status indicates a failure.
Anomaly: An anomaly in monitoring alerts is an event or behavior that deviates from the expected normal operation or behavior of a system.
Problem: A logical entity that groups together several abnormal incidents sharing the same root cause in order to consolidate symptoms and avoid duplicate alerts.
Root Cause Analysis (RCA): A process aimed at identifying the underlying cause based on events and context, not just the symptoms visible during an incident.
Principles of automatic analysis & correlation
Data used to group and deduplicate alerts
ServicePilot's advanced algorithms use multiple data types (metrics, traces, flows, events) at all levels (infrastructure, services, applications). The topology of the environment is at the heart of correlation in order to correctly analyze dependencies between services, processes, hosts, containers, etc.
To avoid redundant alerts and simplify incident management, several grouping and deduplication criteria are used:
- L4 dependencies: Dependencies at layer 4 (transport layer) are taken into account to group incidents related to specific network connections
- L7 dependencies: Dependencies at layer 7 (application layer) allow incidents to be grouped based on application protocols and web services
- Same Host: Incidents affecting the same host are grouped together for centralized management
- Same LAN: Incidents occurring on the same local area network (LAN) are also grouped together for more effective analysis
Contextual, temporal and algorithmic correlation
The analysis is not limited to a simple simultaneous trigger (timestamp). It combines context (dependencies, topology, calls, transactions) and historical data to avoid false positives or erroneous conclusions.
For example, if service A slows down and downstream service B slows down, the engine must determine whether this is the cause or another problem (not just “B is slow because A was slow”).
The approach is based on what is known as “fault tree analysis”: using known dependencies, AI traces back the causality tree to identify the probable root cause.
The result: A single “problem” grouping all events related to the same cause, with an identified root entity—avoiding duplicates/multiple alerts for the same issue.
Life cycle of a “Problem” — from detection to resolution
The lifespan of an issue in ServicePilot is managed dynamically to ensure a quick and effective response:
-
Detection of an initial abnormal event causes the creation of an “issue”. An issue is created automatically if an anomaly persists for at least 3 minutes. This ensures that alerts are not triggered by temporary fluctuations.
-
Analysis & correlation period: The ServicePilot engine collects related events, broadens the context (topology, dependencies, traces) and finds the root cause.
-
Real-time update of the “problem feed”: New related events are aggregated to the same problem if they have the same cause. Dynamic addition allows related events to be added subsequently to provide a complete and contextual view of the incident for up to 90 minutes after the problem is created.
-
Automatic closure of the problem occurs when all affected entities return to normal with the possibility of automatic reopening if symptoms reappear during a reopening window of 30 minutes.
Added value for DevOps/SRE/IT teams
By using the new problem alerts, there are many benefits for monitoring teams:
- Better prioritization & triage: By combining impact + root cause + context, teams can decide what to prioritize
- Less alert “noise”: By grouping multiple events into a single issue, you avoid being overwhelmed with redundant alerts for the same cause
- In-depth analysis (infrastructure, applications, database, dependencies): Complex root causes (e.g. memory, Garbage Collector, DB queries, containers, infrastructure, etc.) can be identified
- Reduced MTTR (Mean Time To Repair): Automation and correlation reduce the time spent on diagnosis
The new ServicePilot v12 feature transforms noisy alert streams into actionable problems, accurately identifies root causes and guides teams toward the most impactful actions — a concrete lever for improving the reliability of distributed systems and accelerating incident resolution.
